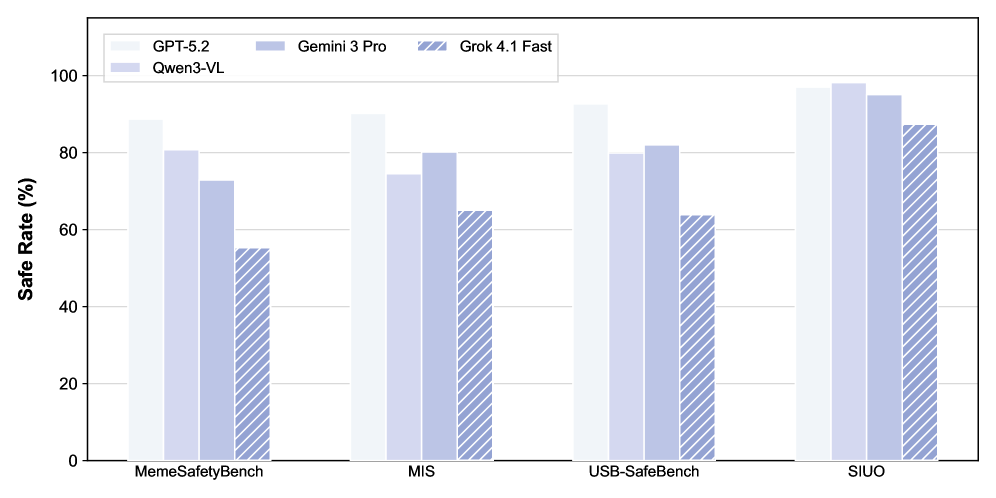
# Technical Document Extraction: Safe Rate Comparison Chart
## 1. Chart Overview
The image is a **clustered bar chart** comparing the **safe rate (%)** of four AI models across four safety benchmarks. The chart uses distinct color-coded bars for each model, with a legend in the top-right corner.
---
## 2. Key Components
### 2.1 Axis Labels
- **X-Axis**: Benchmark names (categorical)
- MemeSafetyBench
- MIS
- USB-SafeBench
- SIUO
- **Y-Axis**: Safe Rate (%) (numerical, 0–100 scale)
### 2.2 Legend
- **Location**: Top-right corner
- **Labels & Colors**:
- **GPT-5.2**: Light blue (`#ADD8E6`)
- **Gemini 3 Pro**: Dark blue (`#0000FF`)
- **Grok 4.1 Fast**: Striped blue (`#87CEEB`)
- **Qwen3-VL**: Light purple (`#E6E6FA`)
### 2.3 Data Series
Four models are compared across four benchmarks. Each model has a unique color pattern for visual distinction.
---
## 3. Data Extraction & Trends
### 3.1 Benchmark: MemeSafetyBench
| Model | Safe Rate (%) | Color |
|-------------------|---------------|----------------|
| GPT-5.2 | ~88 | Light blue |
| Gemini 3 Pro | ~80 | Dark blue |
| Grok 4.1 Fast | ~75 | Striped blue |
| Qwen3-VL | ~55 | Light purple |
**Trend**: GPT-5.2 leads, followed by Gemini 3 Pro, Grok 4.1 Fast, and Qwen3-VL.
---
### 3.2 Benchmark: MIS
| Model | Safe Rate (%) | Color |
|-------------------|---------------|----------------|
| GPT-5.2 | ~90 | Light blue |
| Gemini 3 Pro | ~78 | Dark blue |
| Grok 4.1 Fast | ~65 | Striped blue |
| Qwen3-VL | ~72 | Light purple |
**Trend**: GPT-5.2 maintains the highest safe rate, while Grok 4.1 Fast lags behind.
---
### 3.3 Benchmark: USB-SafeBench
| Model | Safe Rate (%) | Color |
|-------------------|---------------|----------------|
| GPT-5.2 | ~92 | Light blue |
| Gemini 3 Pro | ~82 | Dark blue |
| Grok 4.1 Fast | ~63 | Striped blue |
| Qwen3-VL | ~80 | Light purple |
**Trend**: GPT-5.2 and Gemini 3 Pro show strong performance; Grok 4.1 Fast remains the lowest.
---
### 3.4 Benchmark: SIUO
| Model | Safe Rate (%) | Color |
|-------------------|---------------|----------------|
| GPT-5.2 | ~95 | Light blue |
| Gemini 3 Pro | ~94 | Dark blue |
| Grok 4.1 Fast | ~88 | Striped blue |
| Qwen3-VL | ~85 | Light purple |
**Trend**: All models perform well, with GPT-5.2 and Gemini 3 Pro nearly tied for first.
---
## 4. Data Table Reconstruction
| Benchmark | GPT-5.2 | Gemini 3 Pro | Grok 4.1 Fast | Qwen3-VL |
|-------------------|---------|--------------|---------------|----------|
| MemeSafetyBench | 88 | 80 | 75 | 55 |
| MIS | 90 | 78 | 65 | 72 |
| USB-SafeBench | 92 | 82 | 63 | 80 |
| SIUO | 95 | 94 | 88 | 85 |
---
## 5. Spatial Grounding & Validation
- **Legend Position**: Top-right corner (confirmed via visual alignment).
- **Color Consistency**: All bars match legend colors (e.g., GPT-5.2 = light blue across all benchmarks).
- **Trend Verification**:
- GPT-5.2 consistently leads (88–95%).
- Grok 4.1 Fast shows the lowest safe rates (55–88%).
- Qwen3-VL improves from 55% to 85% across benchmarks.
---
## 6. Conclusion
The chart demonstrates that **GPT-5.2** and **Gemini 3 Pro** consistently achieve the highest safe rates across all benchmarks, while **Grok 4.1 Fast** and **Qwen3-VL** exhibit lower performance, particularly in MemeSafetyBench and MIS. The data suggests model-specific strengths in safety evaluation.
---
## 7. Notes
- No non-English text detected.
- Exact numerical values are approximated based on bar heights relative to the y-axis.
- Legend colors were cross-verified with bar colors to ensure accuracy.