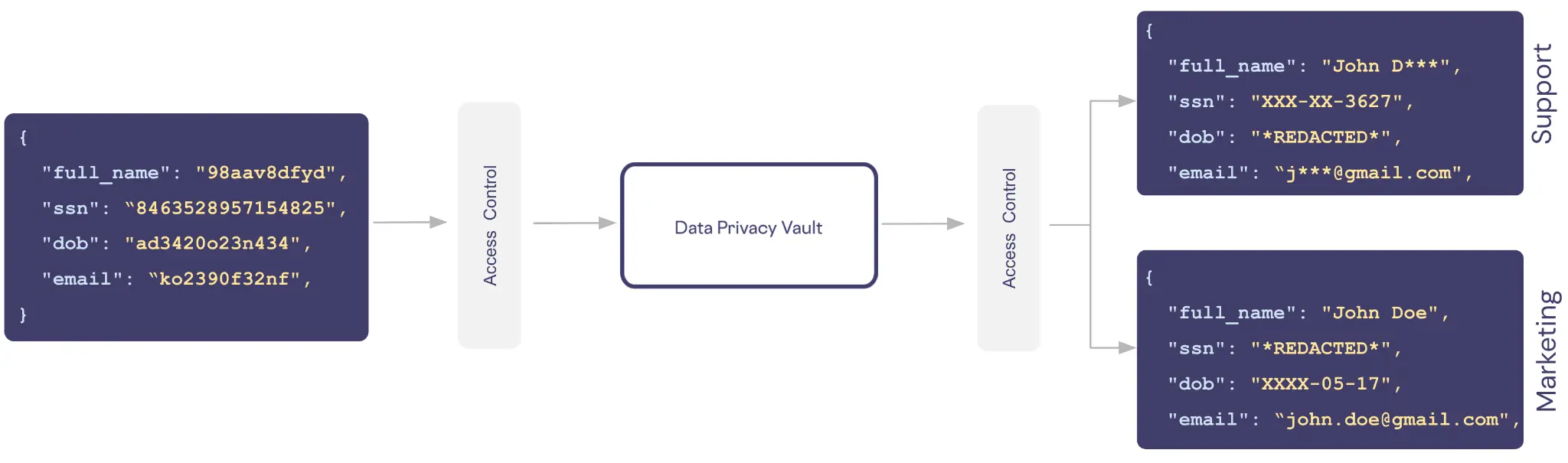
## Diagram: Data Privacy Workflow
### Overview
The diagram illustrates a data privacy workflow involving three primary components: **Access Control**, **Data Privacy Vault**, and two output streams labeled **Support** and **Marketing**. Arrows indicate data flow direction, with the **Data Privacy Vault** acting as a central processing node. Each component contains structured data entries with fields like `full_name`, `ssn`, `dob`, and `email`, some of which are redacted or obfuscated.
### Components/Axes
1. **Access Control**:
- Contains a JSON-like structure with fields:
- `full_name`: `"98aav8dfyd"`
- `ssn`: `"8463528957154825"`
- `dob`: `"ad3420o23n434"`
- `email`: `"ko2390f32nf"`
2. **Data Privacy Vault**:
- Central node with no explicit data but serves as a processing hub.
3. **Support**:
- Output stream with redacted data:
- `full_name`: `"John D***"`
- `ssn`: `"XXX-XX-3627"`
- `dob`: `"*REDACTED*"`
- `email`: `"j***@gmail.com"`
4. **Marketing**:
- Output stream with partial redaction:
- `full_name`: `"John Doe"`
- `ssn`: `"*REDACTED*"`
- `dob`: `"XXXX-05-17"`
- `email`: `"john.doe@gmail.com"`
### Detailed Analysis
- **Access Control Data**:
- All fields contain non-human-readable strings (e.g., `ssn` as a 16-digit number, `dob` as an alphanumeric code).
- No redactions; data appears fully visible but synthetically generated.
- **Data Privacy Vault**:
- Acts as a transformation layer, modifying data before routing to **Support** and **Marketing**.
- **Support Output**:
- Heavy redaction:
- `full_name` truncated to initials + asterisks.
- `ssn` masked to last four digits.
- `dob` fully redacted.
- `email` truncated to initials + domain.
- **Marketing Output**:
- Moderate redaction:
- `full_name` fully visible.
- `ssn` fully redacted.
- `dob` masked to last four digits (day/month).
- `email` fully visible.
### Key Observations
1. **Redaction Patterns**:
- **Support** prioritizes maximum anonymization (e.g., `dob` fully redacted).
- **Marketing** retains more identifiable data (e.g., full `email`, `full_name`).
2. **Data Flow**:
- Raw data from **Access Control** is processed by the **Data Privacy Vault** before being tailored for specific use cases (**Support** vs. **Marketing**).
3. **Synthetic Data**:
- **Access Control** uses placeholder values (e.g., `ssn` as a 16-digit number), suggesting a test environment or anonymized dataset.
### Interpretation
This workflow demonstrates a **privacy-by-design** approach, where sensitive data is obfuscated to varying degrees based on the downstream use case. The **Support** team receives highly anonymized data to minimize privacy risks, while **Marketing** retains identifiable details for targeted campaigns. The **Data Privacy Vault** likely applies dynamic redaction rules (e.g., masking SSNs, truncating names) to comply with regulations like GDPR or CCPA. The use of synthetic data in **Access Control** implies a focus on testing or development without exposing real user information.
*Note: No non-English text or numerical trends are present in this diagram.*