TECHNICAL ASSET FINGERPRINT
f107f2cd03e3a02572ffbd45
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
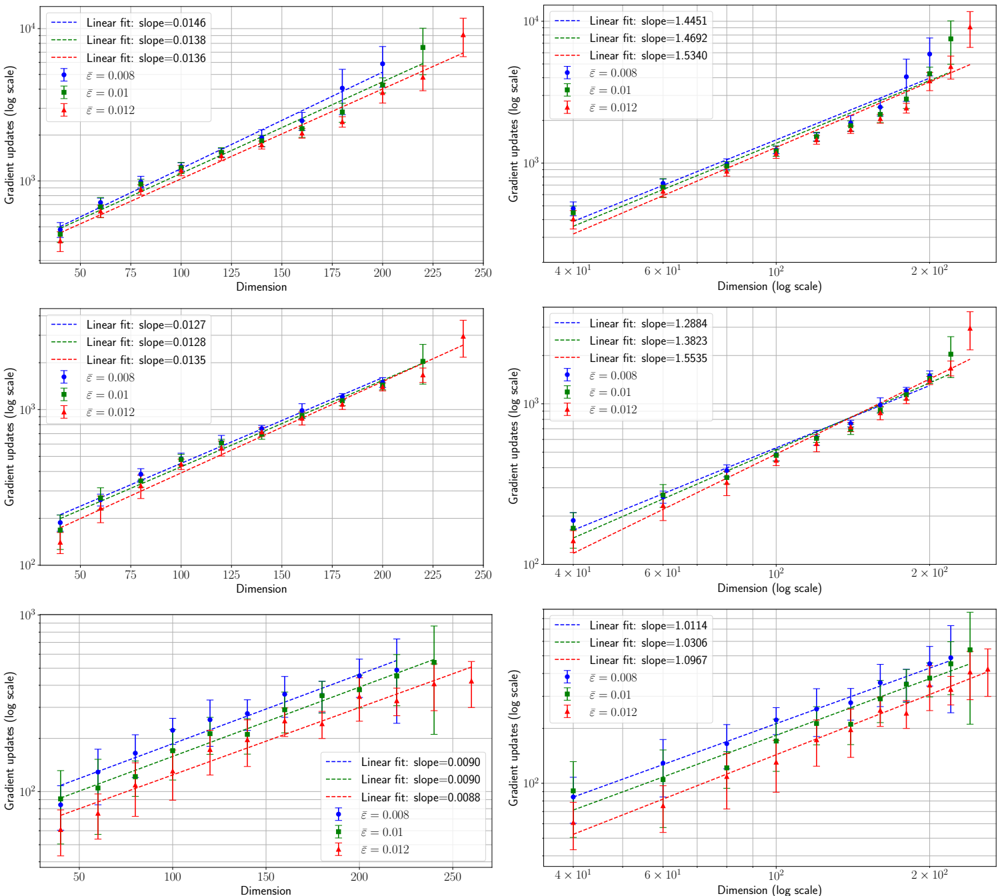
## Chart: Gradient Updates vs. Dimension
### Overview
The image presents six scatter plots, each displaying the relationship between "Gradient updates (log scale)" and "Dimension". The plots are arranged in a 2x3 grid. Each plot shows data for three different values of epsilon (ε = 0.008, ε = 0.01, and ε = 0.012), along with linear fits for each epsilon value. The x-axis represents "Dimension," and the y-axis represents "Gradient updates (log scale)". The left column uses a linear scale for the x-axis, while the right column uses a logarithmic scale.
### Components/Axes
* **Y-axis (all plots):** "Gradient updates (log scale)". The scale ranges from approximately 10^2 to 10^4.
* **X-axis (left column):** "Dimension". The scale ranges from 50 to 250 in linear increments.
* **X-axis (right column):** "Dimension (log scale)". The scale ranges from approximately 4 x 10^1 to 2 x 10^2 in logarithmic increments.
* **Legend (all plots):** Located in the top-left corner of each plot.
* Blue: Linear fit for ε = 0.008
* Green: Linear fit for ε = 0.01
* Red: Linear fit for ε = 0.012
* Blue markers: ε = 0.008
* Green markers: ε = 0.01
* Red markers: ε = 0.012
### Detailed Analysis
**Top-Left Plot:**
* X-axis: Dimension (linear scale)
* Linear fit (blue, ε = 0.008): Slope = 0.0146. The blue data points increase approximately linearly from ~300 at dimension 50 to ~3000 at dimension 250.
* Linear fit (green, ε = 0.01): Slope = 0.0138. The green data points increase approximately linearly from ~400 at dimension 50 to ~2500 at dimension 250.
* Linear fit (red, ε = 0.012): Slope = 0.0136. The red data points increase approximately linearly from ~500 at dimension 50 to ~2500 at dimension 250.
**Top-Right Plot:**
* X-axis: Dimension (log scale)
* Linear fit (blue, ε = 0.008): Slope = 1.4451. The blue data points increase approximately linearly from ~300 at dimension 40 to ~8000 at dimension 200.
* Linear fit (green, ε = 0.01): Slope = 1.4692. The green data points increase approximately linearly from ~400 at dimension 40 to ~9000 at dimension 200.
* Linear fit (red, ε = 0.012): Slope = 1.5340. The red data points increase approximately linearly from ~500 at dimension 40 to ~12000 at dimension 200.
**Middle-Left Plot:**
* X-axis: Dimension (linear scale)
* Linear fit (blue, ε = 0.008): Slope = 0.0127. The blue data points increase approximately linearly from ~250 at dimension 50 to ~2000 at dimension 250.
* Linear fit (green, ε = 0.01): Slope = 0.0128. The green data points increase approximately linearly from ~300 at dimension 50 to ~2200 at dimension 250.
* Linear fit (red, ε = 0.012): Slope = 0.0135. The red data points increase approximately linearly from ~400 at dimension 50 to ~2500 at dimension 250.
**Middle-Right Plot:**
* X-axis: Dimension (log scale)
* Linear fit (blue, ε = 0.008): Slope = 1.2884. The blue data points increase approximately linearly from ~250 at dimension 40 to ~4000 at dimension 200.
* Linear fit (green, ε = 0.01): Slope = 1.3823. The green data points increase approximately linearly from ~300 at dimension 40 to ~6000 at dimension 200.
* Linear fit (red, ε = 0.012): Slope = 1.5535. The red data points increase approximately linearly from ~400 at dimension 40 to ~10000 at dimension 200.
**Bottom-Left Plot:**
* X-axis: Dimension (linear scale)
* Linear fit (blue, ε = 0.008): Slope = 0.0090. The blue data points increase approximately linearly from ~150 at dimension 50 to ~700 at dimension 250.
* Linear fit (green, ε = 0.01): Slope = 0.0090. The green data points increase approximately linearly from ~200 at dimension 50 to ~800 at dimension 250.
* Linear fit (red, ε = 0.012): Slope = 0.0088. The red data points increase approximately linearly from ~200 at dimension 50 to ~700 at dimension 250.
**Bottom-Right Plot:**
* X-axis: Dimension (log scale)
* Linear fit (blue, ε = 0.008): Slope = 1.0114. The blue data points increase approximately linearly from ~150 at dimension 40 to ~1500 at dimension 200.
* Linear fit (green, ε = 0.01): Slope = 1.0306. The green data points increase approximately linearly from ~200 at dimension 40 to ~2000 at dimension 200.
* Linear fit (red, ε = 0.012): Slope = 1.0967. The red data points increase approximately linearly from ~200 at dimension 40 to ~2500 at dimension 200.
### Key Observations
* In all plots, the gradient updates generally increase with dimension.
* The linear fits suggest a roughly linear relationship between dimension and gradient updates, especially when the x-axis is on a linear scale.
* The slopes of the linear fits vary across the different plots, indicating that the rate of increase in gradient updates with dimension depends on the specific scenario represented by each plot.
* The plots on the right (log scale for dimension) show a steeper increase in gradient updates compared to the plots on the left (linear scale for dimension), as indicated by the larger slope values.
* For a given dimension, a higher epsilon value generally corresponds to a higher gradient update value.
### Interpretation
The plots illustrate how gradient updates (on a log scale) change with increasing dimension for different values of epsilon. The use of both linear and logarithmic scales for the dimension axis provides different perspectives on the relationship. The logarithmic scale compresses the higher dimension values, making it easier to visualize the trend over a wider range.
The increasing gradient updates with dimension suggest that as the complexity of the model (represented by dimension) increases, the magnitude of the updates required during training also increases. The different slopes indicate that this relationship is not constant and depends on other factors.
The effect of epsilon is also notable. A higher epsilon value generally leads to larger gradient updates, which could be related to the learning rate or some other parameter influencing the training process.
The error bars on the data points indicate the variability or uncertainty in the gradient updates. The size of these error bars could provide insights into the stability and reliability of the training process.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Line Charts: Gradient Updates vs. Dimension
### Overview
The image contains six line charts arranged in two columns (linear and log-scale x-axis) and three rows (different slope ranges). Each chart visualizes the relationship between **dimension** (x-axis) and **gradient updates** (y-axis, log scale), with linear fits and data points for three epsilon values (ε = 0.008, 0.01, 0.012). The charts demonstrate consistent upward trends, with slopes varying across subplots.
---
### Components/Axes
- **X-axis**:
- Left column: Linear scale (50–250).
- Right column: Log scale (4×10¹–2×10²).
- **Y-axis**: "Gradient updates (log scale)" across all charts.
- **Legends**:
- Positioned in the top-left of each chart.
- Three lines per chart:
- **Blue (dashed)**: Linear fit with slope (e.g., 0.0146).
- **Green (dotted)**: Linear fit with slope (e.g., 0.0138).
- **Red (dash-dot)**: Linear fit with slope (e.g., 0.0136).
- Three data point markers:
- **Blue circles**: ε = 0.008.
- **Green squares**: ε = 0.01.
- **Red triangles**: ε = 0.012.
---
### Detailed Analysis
#### Top-Left Chart (Linear X-axis, Slope ~0.014)
- **Slope Values**:
- Blue: 0.0146
- Green: 0.0138
- Red: 0.0136
- **Data Points**:
- ε = 0.008 (blue): Gradient updates increase from ~10³ to ~10⁴ as dimension rises from 50 to 250.
- ε = 0.01 (green): Similar trend, slightly lower than blue.
- ε = 0.012 (red): Slightly lower than green, with larger error bars.
- **Trend**: All lines slope upward, with blue (ε = 0.008) consistently highest.
#### Top-Right Chart (Log X-axis, Slope ~1.4–1.5)
- **Slope Values**:
- Blue: 1.4451
- Green: 1.4692
- Red: 1.5340
- **Data Points**:
- ε = 0.008 (blue): Gradient updates rise from ~10³ to ~10⁴ as dimension increases from 40 to 200.
- ε = 0.01 (green): Slightly higher than blue.
- ε = 0.012 (red): Highest slope, with larger error bars.
- **Trend**: Lines converge at lower dimensions but diverge at higher dimensions.
#### Middle-Left Chart (Linear X-axis, Slope ~0.012–0.013)
- **Slope Values**:
- Blue: 0.0127
- Green: 0.0128
- Red: 0.0135
- **Data Points**:
- ε = 0.008 (blue): Gradient updates increase from ~10³ to ~10⁴ as dimension rises from 50 to 250.
- ε = 0.01 (green): Slightly higher than blue.
- ε = 0.012 (red): Highest slope, with larger error bars.
- **Trend**: Lines are nearly parallel, with red (ε = 0.012) slightly steeper.
#### Middle-Right Chart (Log X-axis, Slope ~1.2–1.5)
- **Slope Values**:
- Blue: 1.2884
- Green: 1.3823
- Red: 1.5535
- **Data Points**:
- ε = 0.008 (blue): Gradient updates rise from ~10² to ~10³ as dimension increases from 40 to 200.
- ε = 0.01 (green): Slightly higher than blue.
- ε = 0.012 (red): Steepest slope, with larger error bars.
- **Trend**: Lines diverge significantly at higher dimensions.
#### Bottom-Left Chart (Linear X-axis, Slope ~0.009)
- **Slope Values**:
- Blue: 0.0090
- Green: 0.0090
- Red: 0.0088
- **Data Points**:
- ε = 0.008 (blue): Gradient updates increase from ~10² to ~10³ as dimension rises from 50 to 250.
- ε = 0.01 (green): Identical slope to blue.
- ε = 0.012 (red): Slightly lower slope.
- **Trend**: Lines are nearly flat, with minimal variation between ε values.
#### Bottom-Right Chart (Log X-axis, Slope ~1.0–1.1)
- **Slope Values**:
- Blue: 1.0114
- Green: 1.0306
- Red: 1.0967
- **Data Points**:
- ε = 0.008 (blue): Gradient updates rise from ~10² to ~10³ as dimension increases from 40 to 200.
- ε = 0.01 (green): Slightly higher than blue.
- ε = 0.012 (red): Steepest slope, with larger error bars.
- **Trend**: Lines diverge at higher dimensions, with red (ε = 0.012) showing the sharpest increase.
---
### Key Observations
1. **Upward Trends**: All charts show gradient updates increasing with dimension, confirming a positive correlation.
2. **Slope Variability**:
- Higher ε values (e.g., 0.012) often correspond to steeper slopes, suggesting ε influences the rate of gradient updates.
- In log-scale x-axis charts, slopes are generally higher than linear-scale counterparts.
3. **Error Bars**: Larger error bars for ε = 0.012 (red) across most charts, indicating greater variability in gradient updates for this parameter.
4. **Convergence/Divergence**:
- In log-scale charts, lines converge at lower dimensions but diverge at higher dimensions, highlighting ε-dependent scaling behavior.
---
### Interpretation
The charts demonstrate that **gradient updates scale with dimension**, with the rate of increase modulated by the parameter ε. Higher ε values (e.g., 0.012) consistently produce steeper slopes, implying a stronger dependency on dimension under these conditions. The linear fits suggest a proportional relationship, but the log-scale x-axis charts reveal exponential-like growth at higher dimensions. The error bars for ε = 0.012 indicate higher uncertainty, possibly due to increased sensitivity to dimension changes. These results could inform optimization strategies in high-dimensional systems, where ε tuning might balance efficiency and stability.
DECODING INTELLIGENCE...