## Flowchart: Agent Development and Benchmarking Process
### Overview
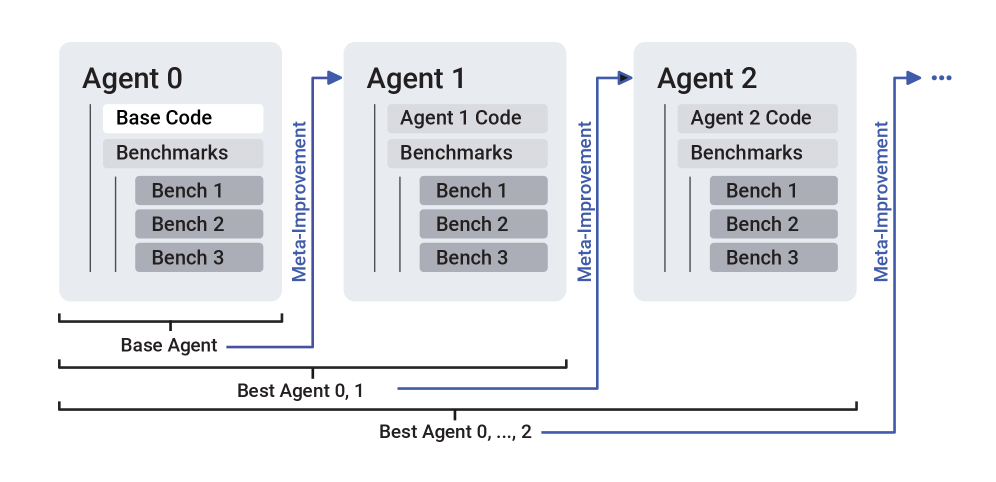
The diagram illustrates a multi-agent iterative improvement process where each agent's code is refined through benchmark evaluations and meta-improvement cycles. Three agents (0, 1, 2) are shown with explicit connections, suggesting a scalable system (indicated by "..." for additional agents).
### Components/Axes
1. **Agents**:
- Agent 0 (Base Agent)
- Agent 1
- Agent 2
- ... (implied continuation)
2. **Code Components**:
- Base Code (Agent 0)
- Agent 1 Code
- Agent 2 Code
3. **Evaluation Framework**:
- Benchmarks (3 per agent: Bench 1, Bench 2, Bench 3)
4. **Meta-Improvement Arrows**:
- Directed from Agent 0 → Agent 1 → Agent 2 → ...
- Label: "Meta-Improvement"
### Detailed Analysis
- **Agent 0**:
- Contains "Base Code" (highlighted)
- Three benchmarks (Bench 1-3)
- Labeled as "Base Agent"
- **Agent 1**:
- Contains "Agent 1 Code"
- Three benchmarks (Bench 1-3)
- Connected to Agent 0 via "Meta-Improvement" arrow
- **Agent 2**:
- Contains "Agent 2 Code"
- Three benchmarks (Bench 1-3)
- Connected to Agent 1 via "Meta-Improvement" arrow
- **Best Agent Selection**:
- "Best Agent 0, 1" (bottom-left)
- "Best Agent 0, ..., 2" (bottom-right)
- Indicates iterative selection across agents
### Key Observations
1. **Iterative Refinement**: Each agent's code is positioned as an improvement over the previous through meta-improvement cycles.
2. **Benchmark Consistency**: All agents share identical benchmark structures (3 per agent), suggesting standardized evaluation criteria.
3. **Scalability**: The "..." notation implies the system can accommodate additional agents beyond Agent 2.
4. **Hierarchical Selection**: The "Best Agent" labels indicate a comparative evaluation process across agents.
### Interpretation
This diagram represents an evolutionary optimization framework where:
1. **Base Agent (Agent 0)** serves as the initial reference point
2. **Meta-Improvement** arrows suggest knowledge transfer or algorithmic refinement between agents
3. **Benchmarking** acts as the evaluation mechanism for code performance
4. **Best Agent Selection** implies a competitive process where agents are ranked based on benchmark results
The structure suggests a reinforcement learning or genetic algorithm approach where:
- Each new agent incorporates improvements from previous iterations
- Benchmarks provide objective performance metrics
- The "Best Agent" selection represents the global optimum across iterations
Notably, the absence of quantitative performance metrics in the diagram leaves the exact nature of "improvement" undefined - it could represent speed, accuracy, resource efficiency, or other measurable criteria. The consistent benchmark structure across agents implies standardized evaluation parameters, while the meta-improvement arrows suggest cumulative knowledge transfer between iterations.