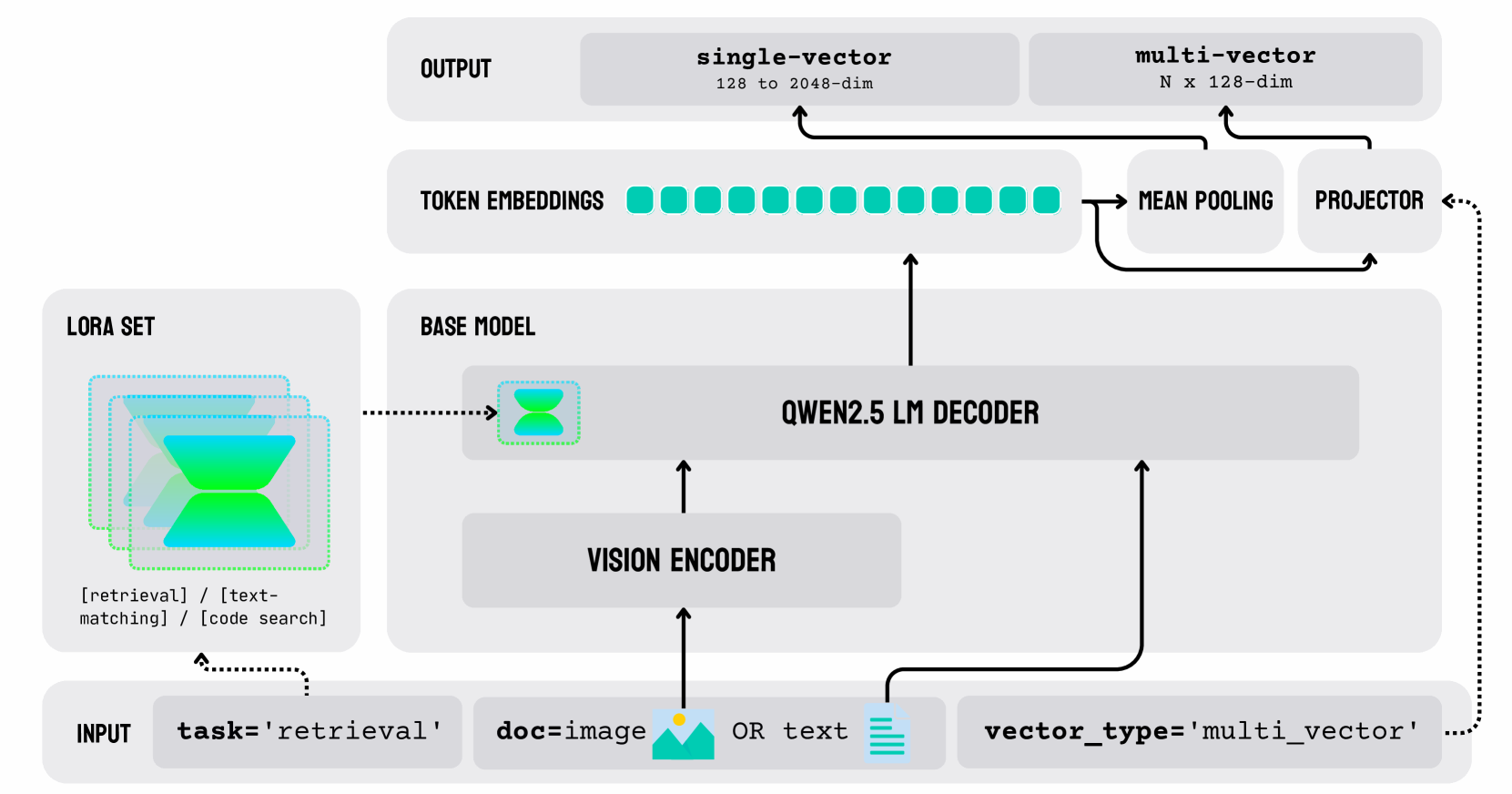
## Diagram Type: Neural Network Architecture
### Overview
The image depicts a neural network architecture designed for a specific task, which appears to be related to image or text retrieval. The architecture is composed of several layers, including an input layer, a vision encoder, a base model, a decoder, and an output layer. The diagram also includes a LORA set and a token embeddings layer.
### Components/Axes
- **Input Layer**: This layer receives the input data, which can be either an image or text.
- **Vision Encoder**: This layer processes the input data to extract features. It is represented by a green icon with a magnifying glass.
- **Base Model**: This layer is the main component of the network, which is represented by a blue icon with a brain.
- **Decoder**: This layer takes the output from the base model and generates the final output.
- **Output Layer**: This layer produces the final result of the task.
- **LORA Set**: This layer is used for fine-tuning the base model.
- **Token Embeddings**: This layer converts the input data into numerical vectors.
- **Mean Pooling**: This layer reduces the dimensionality of the token embeddings.
- **Projector**: This layer projects the mean-pooled embeddings into a lower-dimensional space.
- **Qwen2.5 LM Decoder**: This layer generates the final output based on the projected embeddings.
### Detailed Analysis or ### Content Details
- **Input Layer**: The input data can be either an image or text. The input is represented by a green icon with a magnifying glass.
- **Vision Encoder**: The vision encoder processes the input data to extract features. The output of the vision encoder is a set of token embeddings, which are represented by a series of green dots.
- **Base Model**: The base model is represented by a blue icon with a brain. It takes the token embeddings as input and generates a set of multi-vector outputs.
- **Decoder**: The decoder takes the multi-vector outputs from the base model and generates the final output. The output is represented by a green icon with a speech bubble.
- **Output Layer**: The output layer produces the final result of the task. The output is represented by a green icon with a checkmark.
- **LORA Set**: The LORA set is used for fine-tuning the base model. It is represented by a blue icon with a gear.
- **Token Embeddings**: The token embeddings are converted into numerical vectors using the token embeddings layer. The output of the token embeddings layer is a set of token embeddings, which are represented by a series of green dots.
- **Mean Pooling**: The mean pooling layer reduces the dimensionality of the token embeddings. The output of the mean pooling layer is a set of mean-pooled embeddings, which are represented by a series of green dots.
- **Projector**: The projector layer projects the mean-pooled embeddings into a lower-dimensional space. The output of the projector layer is a set of multi-vector outputs, which are represented by a series of green dots.
- **Qwen2.5 LM Decoder**: The Qwen2.5 LM decoder generates the final output based on the projected embeddings. The output is represented by a green icon with a speech bubble.
### Key Observations
- The architecture is designed for a specific task, which appears to be related to image or text retrieval.
- The vision encoder is used to extract features from the input data.
- The base model is used to generate the multi-vector outputs.
- The decoder is used to generate the final output.
- The LORA set is used for fine-tuning the base model.
- The token embeddings layer is used to convert the input data into numerical vectors.
- The mean pooling layer is used to reduce the dimensionality of the token embeddings.
- The projector layer is used to project the mean-pooled embeddings into a lower-dimensional space.
- The Qwen2.5 LM decoder is used to generate the final output.
### Interpretation
The architecture depicted in the image is designed for a specific task, which appears to be related to image or text retrieval. The vision encoder is used to extract features from the input data, which can be either an image or text. The base model is used to generate the multi-vector outputs, which are then used by the decoder to generate the final output. The LORA set is used for fine-tuning the base model, which can improve the accuracy of the output. The token embeddings layer is used to convert the input data into numerical vectors, which are then used by the mean pooling layer to reduce the dimensionality of the token embeddings. The projector layer is used to project the mean-pooled embeddings into a lower-dimensional space, which is then used by the Qwen2.5 LM decoder to generate the final output. Overall, the architecture is designed to be efficient and accurate in generating the final output.