## Diagram: QWEN2.5 LM Decoder Architecture
### Overview
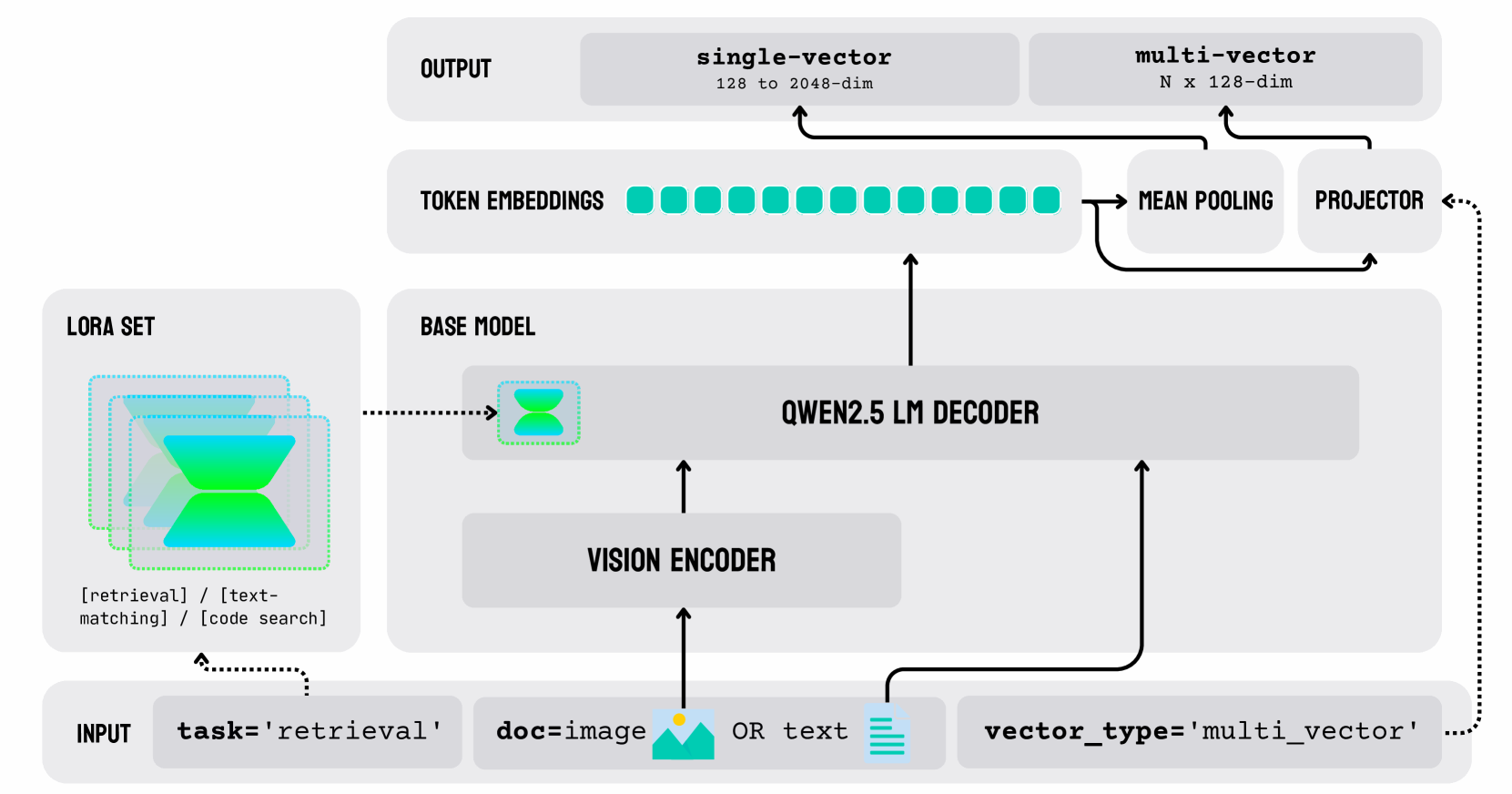
The image is a diagram illustrating the architecture of a system utilizing a QWEN2.5 LM Decoder. It shows the flow of data from input to output, highlighting key components such as LORA Set, Base Model, Vision Encoder, Token Embeddings, Mean Pooling, and Projector. The diagram also specifies the dimensions of the vectors at different stages.
### Components/Axes
* **INPUT:** Contains the task, document type, and vector type.
* `task='retrieval'`
* `doc=image` OR `text` (represented by an image icon and a text icon)
* `vector_type='multi_vector'`
* **LORA SET:** Represents a set of tasks, including:
* `[retrieval]`
* `[text-matching]`
* `[code search]`
* **BASE MODEL:** Contains the QWEN2.5 LM DECODER.
* **VISION ENCODER:** Encodes the visual input.
* **TOKEN EMBEDDINGS:** Represents the token embeddings (visualized as a series of teal squares).
* **OUTPUT:**
* `single-vector`: 128 to 2048-dim
* `multi-vector`: N x 128-dim
* **MEAN POOLING:** Pools the token embeddings.
* **PROJECTOR:** Projects the pooled embeddings.
### Detailed Analysis
1. **Input:** The process begins with an input that specifies the task as 'retrieval'. The document can be either an image or text. The vector type is set to 'multi_vector'.
2. **LORA Set:** The LORA set contains tasks such as retrieval, text-matching, and code search.
3. **Vision Encoder:** If the input is an image, it is processed by the Vision Encoder.
4. **Base Model:** The Vision Encoder's output, or the text input, is fed into the QWEN2.5 LM Decoder within the Base Model.
5. **Token Embeddings:** The decoder generates token embeddings, represented by a series of teal squares.
6. **Mean Pooling:** The token embeddings are then processed by Mean Pooling.
7. **Projector:** The output of the Mean Pooling is fed into a Projector.
8. **Output:** The system produces two types of outputs: a single-vector with dimensions ranging from 128 to 2048, and a multi-vector with dimensions N x 128. The projector also feeds back into the token embeddings.
### Key Observations
* The diagram illustrates a multi-modal system capable of processing both image and text inputs.
* The system uses a QWEN2.5 LM Decoder as its core component.
* The output can be either a single vector or a multi-vector, depending on the application.
* There is a feedback loop from the Projector back to the Token Embeddings.
### Interpretation
The diagram depicts a sophisticated architecture designed for retrieval tasks, capable of handling both image and text inputs. The use of a QWEN2.5 LM Decoder suggests a focus on language understanding and generation. The presence of both single-vector and multi-vector outputs indicates flexibility in how the information is represented and used downstream. The feedback loop from the Projector to the Token Embeddings likely serves to refine the embeddings and improve the system's performance over time. The LORA set suggests the model can be adapted to different tasks.