\n
## Diagram: Multimodal Model Architecture
### Overview
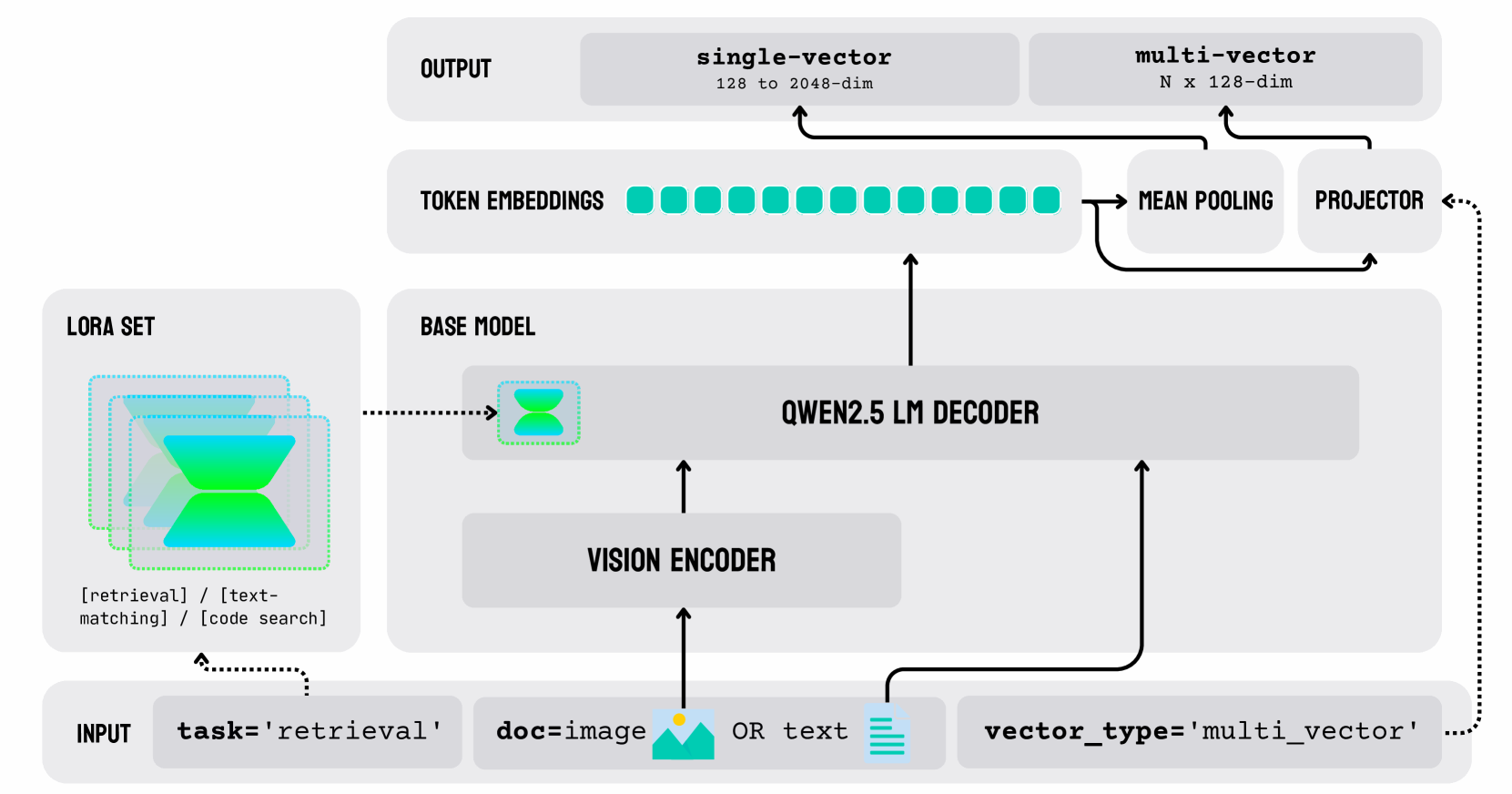
This diagram illustrates the architecture of a multimodal model, likely for retrieval or text-matching tasks. The model takes either an image or text as input, processes it through a vision encoder and a QWEN2.5 LM decoder, and outputs either a single-vector or a multi-vector representation. A LORA set is used to modify the base model.
### Components/Axes
The diagram consists of several key components connected by arrows indicating data flow:
* **INPUT:** Labeled with "task='retrieval'" and options for input type: "doc-image" or "text", and "vector_type='multi_vector'".
* **LORA SET:** A teal and blue hexagonal shape with a dotted outline.
* **BASE MODEL:** A purple hexagonal shape.
* **VISION ENCODER:** A rectangular block.
* **QWEN2.5 LM DECODER:** A larger rectangular block.
* **TOKEN EMBEDDINGS:** A series of green circles.
* **SINGLE-VECTOR:** A rectangular block labeled "128 to 2048-dim".
* **MULTI-VECTOR:** A rectangular block labeled "N x 128-dim".
* **MEAN POOLING:** A rectangular block.
* **PROJECTOR:** A rectangular block.
* **OUTPUT:** A rectangular block at the top.
Arrows indicate the flow of data between these components. Dotted arrows represent modifications or adjustments.
### Detailed Analysis or Content Details
The diagram shows the following data flow:
1. **Input:** The process begins with an input, which can be either a document image ("doc-image") or text. The task is specified as "retrieval", and the vector type is "multi_vector".
2. **Vision Encoder:** The input (image or text) is fed into a Vision Encoder.
3. **QWEN2.5 LM Decoder:** The output of the Vision Encoder is then passed to the QWEN2.5 LM Decoder.
4. **Token Embeddings:** The output of the QWEN2.5 LM Decoder is converted into Token Embeddings, represented as a sequence of green circles.
5. **Single-Vector/Multi-Vector:** The Token Embeddings are split into two paths:
* One path leads directly to a "single-vector" output, with a dimensionality of 128 to 2048 dimensions.
* The other path goes through "Mean Pooling" and then a "Projector" to produce a "multi-vector" output, with a dimensionality of N x 128 dimensions.
6. **LORA Set & Base Model:** The LORA set modifies the Base Model. The output of the Base Model is then fed into the Vision Encoder.
### Key Observations
* The model supports both image and text inputs.
* The model produces two types of vector representations: single-vector and multi-vector.
* The LORA set is used to adapt the base model for the specific task.
* The diagram highlights the key components and their interactions in a multimodal processing pipeline.
### Interpretation
This diagram depicts a multimodal model designed for retrieval tasks. The use of a Vision Encoder suggests the model can process visual information, while the QWEN2.5 LM Decoder indicates the use of a large language model for understanding and generating text. The LORA set allows for efficient adaptation of a pre-trained base model to the specific retrieval task. The output of both single and multi-vectors suggests the model can be used for different downstream applications, potentially including semantic search and image-text matching. The "N x 128-dim" multi-vector output suggests the model can represent multiple aspects or features of the input data. The diagram emphasizes the integration of visual and textual information for improved retrieval performance.