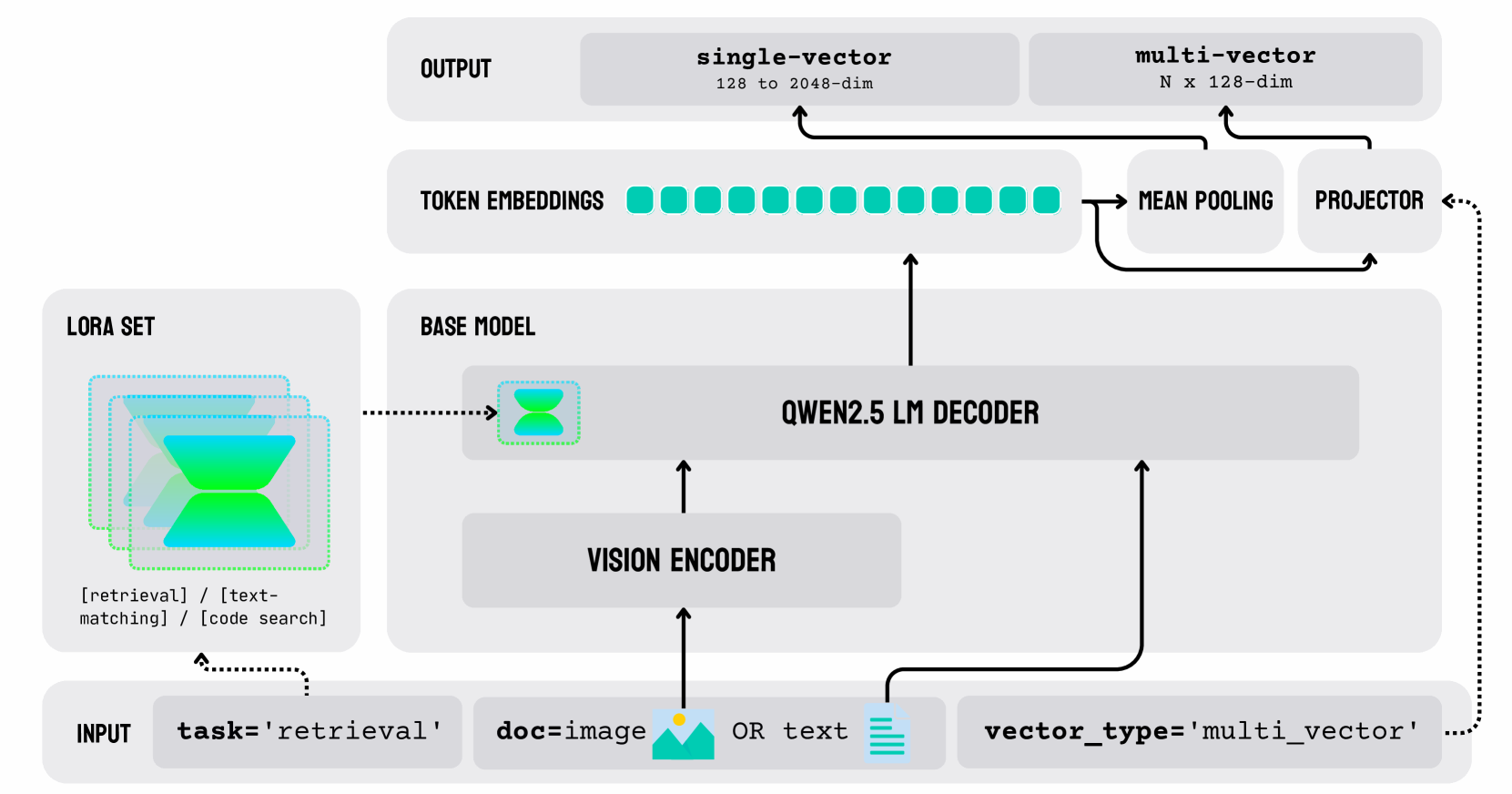
## System Architecture Diagram: Multimodal Retrieval Pipeline
### Overview
The diagram illustrates a technical system for multimodal retrieval tasks, showing the flow from input parameters through processing components to output vectors. It combines vision encoding, language modeling, and vector projection components in a structured pipeline.
### Components/Axes
1. **Input Section** (bottom-left):
- `task='retrieval'`
- `doc=image` (with mountain icon)
- `OR text` (with document icon)
- `vector_type='multi_vector'`
2. **LORA SET** (left-center):
- Contains three overlapping green/blue gradient shapes
- Labeled with: `[retrieval] / [text-matching] / [code search]`
3. **Base Model** (central):
- Contains:
- **QWEN2.5 LM DECODER** (large central component)
- **VISION ENCODER** (below decoder)
4. **Processing Pipeline** (right-center):
- **TOKEN EMBEDDINGS** (10 teal squares)
- **MEAN POOLING** (rectangle)
- **PROJECTOR** (rectangle)
5. **Output Section** (top):
- **single-vector** (128-dim)
- **multi-vector** (N x 128-dim)
### Detailed Analysis
- **Flow Direction**:
- Input → LORA SET → Base Model (Vision Encoder + QWEN2.5 LM Decoder) → Token Embeddings → Mean Pooling → Projector → Outputs
- **Key Connections**:
- Dotted lines connect LORA SET to Base Model
- Solid arrows show processing flow through components
- Dashed line connects input to LORA SET
### Key Observations
1. **Multimodal Capability**: System handles both image (`doc=image`) and text (`OR text`) inputs
2. **Specialized Components**:
- LORA SET specifically targets retrieval/text-matching/code-search tasks
- QWEN2.5 LM Decoder suggests large language model integration
3. **Output Flexibility**:
- Single-vector (128-dim) for basic retrieval
- Multi-vector (N x 128-dim) for batch processing or complex queries
4. **Dimensionality Reduction**:
- Token embeddings (10 elements) → compressed through mean pooling and projector
### Interpretation
This architecture demonstrates a hybrid approach to multimodal retrieval:
- The LORA SET acts as a task-specific adapter layer for different retrieval modalities
- The vision encoder and language model decoder create a unified representation space
- The projection system enables both scalar (single-vector) and array-based (multi-vector) outputs
- The 128-dimensional output suggests optimization for efficient similarity search in vector databases
The system appears designed for tasks requiring both visual understanding (via image input) and semantic text processing, with the LORA SET providing task-specific optimization. The multi-vector output capability indicates support for batch processing or complex query scenarios requiring multiple retrieval results.