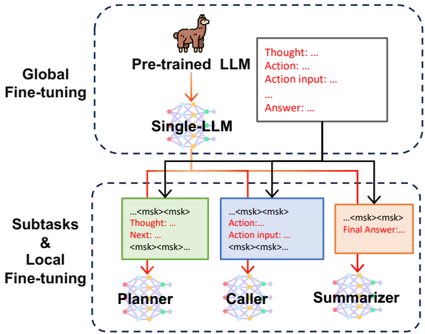
## Diagram: LLM Fine-tuning Process
### Overview
The image illustrates a two-stage fine-tuning process for a Large Language Model (LLM). The process involves global fine-tuning of a pre-trained LLM, followed by local fine-tuning of subtasks.
### Components/Axes
* **Top Region (Global Fine-tuning):**
* Label: "Global Fine-tuning" on the left.
* Component: "Pre-trained LLM" with a llama icon above it.
* Component: "Single-LLM" represented as a neural network diagram.
* Text Box: Contains the following text:
* "Thought: ..."
* "Action: ..."
* "Action input: ..."
* "Answer: ..."
* **Bottom Region (Subtasks & Local Fine-tuning):**
* Label: "Subtasks & Local Fine-tuning" on the left.
* Component: "Planner" represented as a neural network diagram.
* Text Box: Contains the following text:
* "...<msk><msk>..."
* "Thought: ..."
* "Next: ..."
* "<msk><msk>..."
* Component: "Caller" represented as a neural network diagram.
* Text Box: Contains the following text:
* "...<msk><msk>..."
* "Action: ..."
* "Action input: ..."
* "<msk><msk>..."
* Component: "Summarizer" represented as a neural network diagram.
* Text Box: Contains the following text:
* "...<msk><msk>..."
* "Final Answer: ..."
### Detailed Analysis
* **Global Fine-tuning Stage:**
* The "Pre-trained LLM" (with the llama icon) feeds into the "Single-LLM".
* The output of the "Single-LLM" is represented by a black line going to each of the subtasks.
* The "Pre-trained LLM" outputs to a text box containing "Thought", "Action", "Action input", and "Answer".
* **Subtasks & Local Fine-tuning Stage:**
* The "Planner", "Caller", and "Summarizer" are individual neural networks.
* Each subtask receives input from the "Single-LLM" (black line).
* The "Planner" has a text box containing "Thought" and "Next".
* The "Caller" has a text box containing "Action" and "Action input".
* The "Summarizer" has a text box containing "Final Answer".
* The "Planner", "Caller", and "Summarizer" also receive input from the "Pre-trained LLM" (red line).
### Key Observations
* The diagram illustrates a hierarchical approach to fine-tuning an LLM.
* The global fine-tuning stage prepares the LLM for specific subtasks.
* The local fine-tuning stage optimizes the LLM for each subtask.
* The use of "..." indicates that the text boxes contain incomplete information or placeholders.
* The "<msk><msk>" tags suggest masked language modeling or a similar technique.
### Interpretation
The diagram presents a method for improving the performance of LLMs on complex tasks by breaking them down into smaller, more manageable subtasks. The global fine-tuning stage likely aims to adapt the pre-trained LLM to the general domain of the task, while the local fine-tuning stage focuses on optimizing the LLM for each specific subtask. The use of masked language modeling suggests that the fine-tuning process involves predicting missing words or phrases in the input text, which can help the LLM learn to better understand and generate text. The diagram highlights the importance of task decomposition and targeted fine-tuning for achieving optimal performance with LLMs.