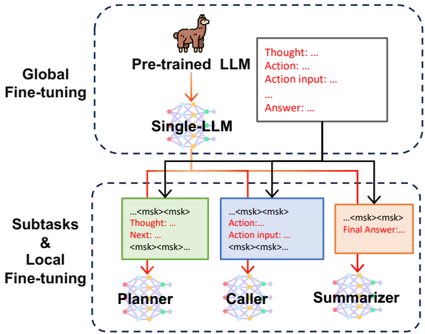
## Diagram: Two-Stage LLM Fine-Tuning Architecture for Task Decomposition
### Overview
The image is a technical diagram illustrating a two-stage process for adapting a large language model (LLM) to perform complex tasks by breaking them down into specialized subtasks. The architecture consists of a global fine-tuning stage followed by a local fine-tuning stage for specific subtask modules.
### Components/Axes
The diagram is divided into two primary sections, demarcated by dashed-line boxes:
1. **Top Section (Global Fine-tuning):**
* **Label:** "Global Fine-tuning" (positioned to the left of the top box).
* **Components:**
* An icon of a llama labeled **"Pre-trained LLM"**.
* A downward arrow pointing to a neural network icon labeled **"Single-LLM"**.
* A text box to the right containing placeholder text in a structured format:
* `Thought:...`
* `Action:...`
* `Action input: ...`
* `...`
* `Answer: ...`
2. **Bottom Section (Subtasks & Local Fine-tuning):**
* **Label:** "Subtasks & Local Fine-tuning" (positioned to the left of the bottom box).
* **Components:** Three colored blocks, each representing a specialized subtask module, connected by arrows from the "Single-LLM" above.
* **Planner (Green Block):**
* Internal Text: `<mks><mks> Thought:... Next: <mks><mks>...`
* **Caller (Blue Block):**
* Internal Text: `Action:... Action input:... <mks><mks>...`
* **Summarizer (Orange Block):**
* Internal Text: `<mks><mks> Final Answer:...`
* Each colored block has a downward arrow pointing to a corresponding neural network icon labeled with the module's name (**Planner**, **Caller**, **Summarizer**).
### Detailed Analysis
* **Flow and Relationships:** The diagram depicts a sequential and hierarchical flow.
1. A **"Pre-trained LLM"** undergoes **"Global Fine-tuning"** to become a **"Single-LLM"** capable of generating structured, step-by-step reasoning (as shown in the adjacent text box with `Thought`, `Action`, etc.).
2. This **"Single-LLM"** then serves as the foundation for the second stage. Its outputs are routed to three specialized modules.
3. The **"Planner"** (green) appears to handle the initial reasoning and planning step (`Thought:... Next:`).
4. The **"Caller"** (blue) seems responsible for executing actions based on the plan (`Action:... Action input:...`).
5. The **"Summarizer"** (orange) is tasked with producing the final output (`Final Answer:...`).
6. Each of these modules undergoes its own **"Local Fine-tuning"** to specialize in its subtask.
* **Textual Elements:** All text is in English. The `<mks>` tags within the subtask blocks appear to be placeholders or markers, possibly indicating segments of text or specific formatting tokens used in the model's processing pipeline.
### Key Observations
* The architecture explicitly separates **general reasoning capability** (developed in the global stage) from **task-specific execution** (honed in the local stage).
* The color-coding (Green/Planner, Blue/Caller, Orange/Summarizer) is consistently applied to the blocks and their corresponding final model icons, providing clear visual association.
* The placeholder text (`...`) indicates that the specific content of thoughts, actions, and answers is variable and generated by the model during operation.
* The diagram emphasizes a **modular design**, where different components can be fine-tuned independently for their respective roles.
### Interpretation
This diagram illustrates a sophisticated approach to making LLMs more reliable and effective for multi-step problem-solving. The core idea is to mimic a human-like workflow: first, understand and plan a task globally; then, delegate specific steps to specialized "experts."
* **What it suggests:** The architecture aims to improve performance on complex tasks by breaking them into manageable subtasks (planning, action execution, summarization). This modularity likely makes the system more interpretable and easier to debug, as each module's role is clear.
* **How elements relate:** The "Single-LLM" acts as a central coordinator or a generalist brain. The specialized modules (Planner, Caller, Summarizer) are like focused assistants that take instructions from the central LLM and perform their specific duties with greater precision due to local fine-tuning.
* **Notable design choice:** The use of structured output formats (`Thought:`, `Action:`, etc.) in both the global and local stages suggests the system relies on a **chain-of-thought** or **reasoning-action** paradigm to maintain transparency and control over the model's process. The `<mks>` tags hint at a technical implementation detail for segmenting or marking these structured outputs during processing.
This two-stage fine-tuning strategy represents a move away from relying on a single, monolithic model for all aspects of a task, towards a more engineered, collaborative system of specialized components.