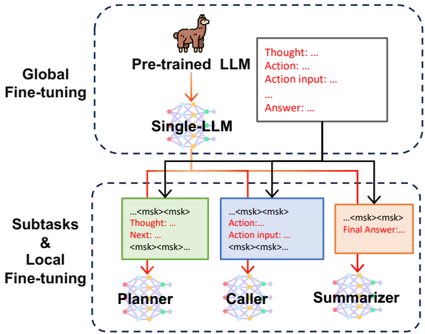
## Diagram: System Architecture for LLM Fine-tuning and Subtask Processing
### Overview
The diagram illustrates a multi-stage system architecture for fine-tuning large language models (LLMs) and processing subtasks. It is divided into two primary sections: **Global Fine-tuning** (top) and **Subtasks & Local Fine-tuning** (bottom). Arrows indicate the flow of information and control between components, with color-coded text boxes representing specific stages of processing.
---
### Components/Axes
1. **Global Fine-tuning Section**:
- **Pre-trained LLM**: A llama icon representing the initial pre-trained model.
- **Single-LLM**: A network diagram symbolizing a single LLM instance.
- Arrows connect "Pre-trained LLM" to "Single-LLM," indicating a transition or refinement process.
2. **Subtasks & Local Fine-tuning Section**:
- **Planner**: A green text box with placeholders like `<msk>` and labels "Thought: ...", "Next: ...".
- **Caller**: A blue text box with "Action: ...", "Action input: ...", and `<msk>` placeholders.
- **Summarizer**: An orange text box with "Final Answer: ..." and `<msk>` placeholders.
- Arrows connect these components in a sequential flow: Planner → Caller → Summarizer.
3. **Control Flow**:
- Red arrows link the Global Fine-tuning section to the Subtasks section, labeled with "Thought: ...", "Action: ...", and "Answer: ...".
- The final output flows from the Summarizer to the Global Fine-tuning section.
---
### Detailed Analysis
- **Textual Elements**:
- **Thought**: Placeholder for reasoning steps (e.g., "Thought: ...").
- **Action**: Placeholder for model actions (e.g., "Action: ...").
- **Action input**: Placeholder for input data (e.g., "Action input: ...").
- **Answer**: Placeholder for intermediate outputs (e.g., "Answer: ...").
- **Final Answer**: Placeholder for the system's final output (e.g., "Final Answer: ...").
- **Color Coding**:
- **Green**: Planner (subtask planning).
- **Blue**: Caller (action execution).
- **Orange**: Summarizer (output synthesis).
- **Red**: Arrows indicating control flow (Thought → Action → Answer → Final Answer).
- **Spatial Grounding**:
- **Top Section**: "Global Fine-tuning" is centered at the top, with "Pre-trained LLM" and "Single-LLM" aligned vertically.
- **Bottom Section**: "Subtasks & Local Fine-tuning" is centered at the bottom, with Planner, Caller, and Summarizer arranged horizontally.
- Arrows originate from the Global Fine-tuning section and terminate in the Subtasks section, with text boxes positioned near the arrows.
---
### Key Observations
1. **Sequential Workflow**: The system processes information in a pipeline: Global Fine-tuning → Subtasks (Planner → Caller → Summarizer) → Global Fine-tuning.
2. **Placeholder Usage**: `<msk>` placeholders suggest masked token inputs for model training or inference.
3. **Color-Coded Roles**: Distinct colors differentiate subtask components, aiding in visual separation of responsibilities.
4. **Cyclical Feedback**: The final output from the Summarizer loops back to the Global Fine-tuning section, implying iterative refinement.
---
### Interpretation
This diagram represents a hybrid system for LLM optimization and task execution. The **Global Fine-tuning** stage likely involves adapting a pre-trained model to a specific domain, while the **Subtasks & Local Fine-tuning** section handles task-specific processing through modular components:
- **Planner**: Generates reasoning steps or task plans.
- **Caller**: Executes actions based on the plan.
- **Summarizer**: Synthesizes results into a final answer.
The cyclical feedback loop suggests the system iteratively refines outputs, potentially improving performance over time. The use of `<msk>` placeholders indicates a focus on masked language modeling techniques, common in transformer-based architectures. The diagram emphasizes modularity, with clear separation between global model adaptation and localized task execution.