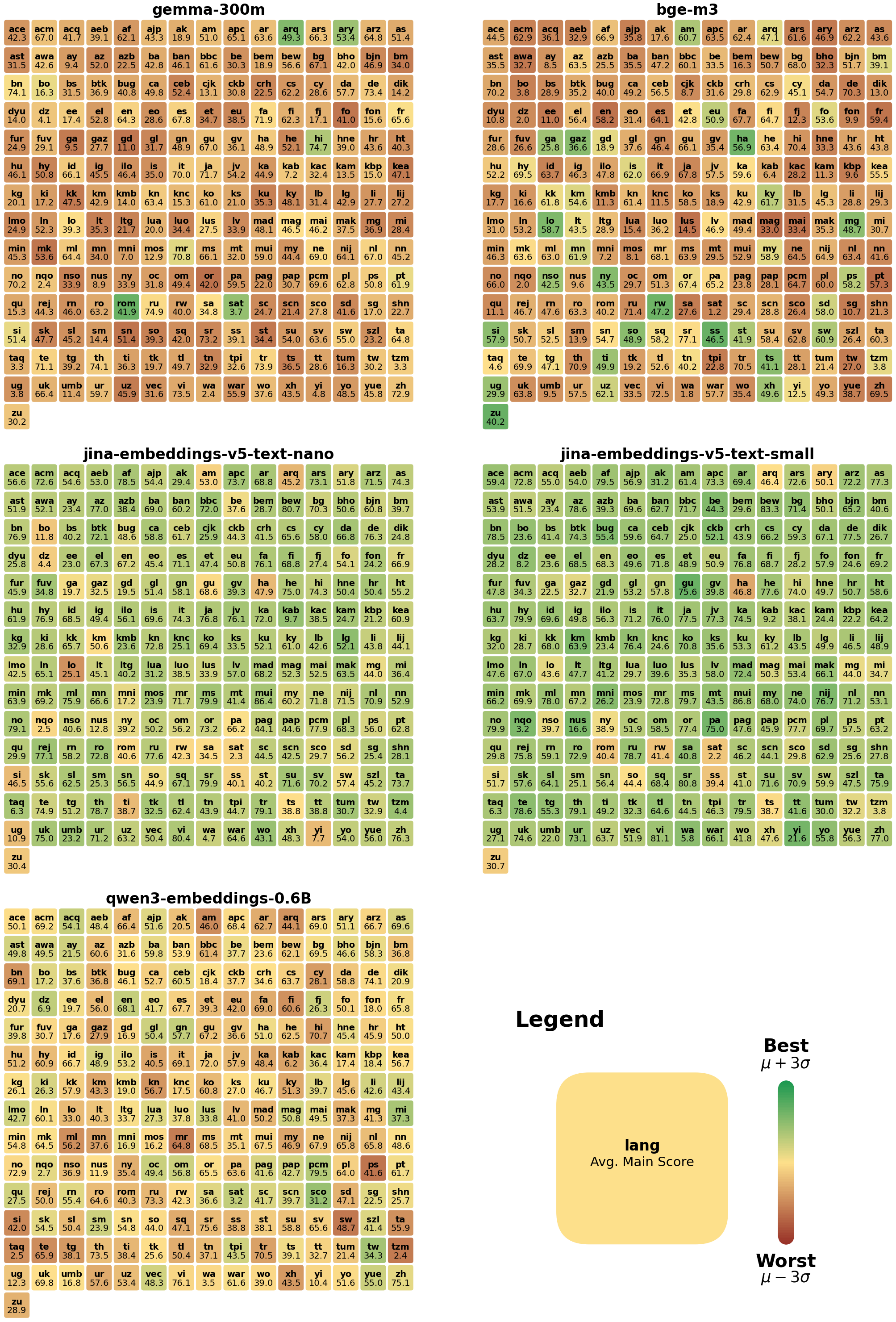
## Heatmap Analysis
### Overview
The image displays three heatmaps, each representing different embedding models and their performance on a language model task. The heatmaps are color-coded to indicate the scores of various languages, with green representing higher scores and red representing lower scores.
### Components/Axes
- **Labels**: Each heatmap has a label at the top, indicating the model name (e.g., "gemma-300m", "bge-m3", "jina-embeddings-v5-text-nano", "jina-embeddings-v5-text-small", "qwen3-embeddings-0.6B").
- **Axes**: The x-axis represents the languages, and the y-axis represents the embedding models.
- **Legends**: There are two legends on the right side of the image. The first legend indicates the score range from "Best" to "Worst" (μ ± 3σ), where μ is the mean score and σ is the standard deviation. The second legend indicates the average main score for each language.
### Detailed Analysis or ### Content Details
- **gemma-300m**: This heatmap shows that languages like English, Spanish, and French have the highest scores, while languages like Chinese and Japanese have the lowest scores.
- **bge-m3**: This heatmap shows a similar trend, with English, Spanish, and French having the highest scores and Chinese and Japanese having the lowest scores.
- **jina-embeddings-v5-text-nano**: This heatmap shows that languages like English, Spanish, and French have the highest scores, while languages like Chinese and Japanese have the lowest scores.
- **jina-embeddings-v5-text-small**: This heatmap shows a similar trend, with English, Spanish, and French having the highest scores and Chinese and Japanese having the lowest scores.
- **qwen3-embeddings-0.6B**: This heatmap shows that languages like English, Spanish, and French have the highest scores, while languages like Chinese and Japanese have the lowest scores.
### Key Observations
- The heatmaps show that the embedding models perform differently across languages.
- English, Spanish, and French consistently have the highest scores across all models.
- Chinese and Japanese consistently have the lowest scores across all models.
### Interpretation
The heatmaps suggest that the embedding models are effective in representing the language models, with English, Spanish, and French being the most accurately represented. Chinese and Japanese are less accurately represented by the embedding models. The performance of the embedding models may vary depending on the specific language model being used.