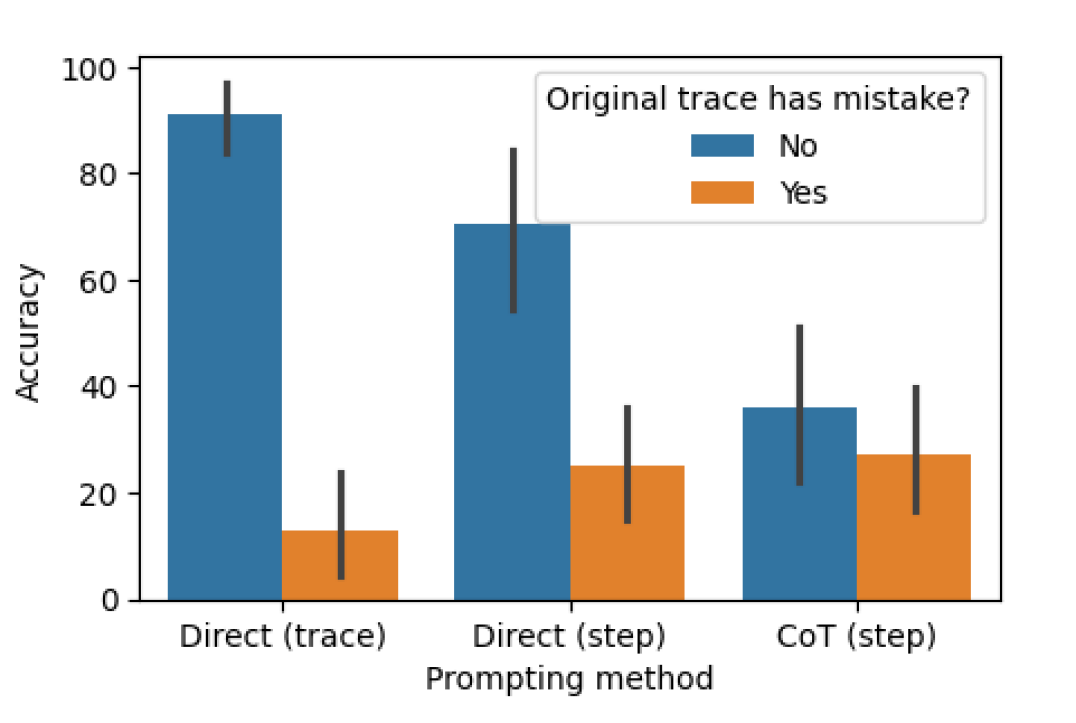
## Bar Chart: Accuracy vs. Prompting Method with and without Original Trace Mistakes
### Overview
The image is a bar chart comparing the accuracy of different prompting methods ("Direct (trace)", "Direct (step)", and "CoT (step)") based on whether the original trace had a mistake ("No" and "Yes"). The chart displays accuracy on the y-axis and prompting method on the x-axis. Error bars are included on each bar.
### Components/Axes
* **Y-axis:** "Accuracy", ranging from 0 to 100 in increments of 20.
* **X-axis:** "Prompting method", with three categories: "Direct (trace)", "Direct (step)", and "CoT (step)".
* **Legend (Top-Right):** "Original trace has mistake?"
* Blue: "No"
* Orange: "Yes"
### Detailed Analysis
Here's a breakdown of the accuracy for each prompting method, separated by whether the original trace had a mistake:
* **Direct (trace):**
* No mistake (Blue): Accuracy is approximately 92%, with an error bar extending from roughly 82% to 100%.
* Yes mistake (Orange): Accuracy is approximately 13%, with an error bar extending from roughly 3% to 24%.
* **Direct (step):**
* No mistake (Blue): Accuracy is approximately 71%, with an error bar extending from roughly 56% to 86%.
* Yes mistake (Orange): Accuracy is approximately 25%, with an error bar extending from roughly 17% to 35%.
* **CoT (step):**
* No mistake (Blue): Accuracy is approximately 36%, with an error bar extending from roughly 25% to 52%.
* Yes mistake (Orange): Accuracy is approximately 27%, with an error bar extending from roughly 17% to 41%.
### Key Observations
* For all prompting methods, accuracy is significantly higher when the original trace does not have a mistake.
* "Direct (trace)" has the highest accuracy when there is no mistake in the original trace.
* "CoT (step)" has the lowest accuracy overall, regardless of whether there is a mistake in the original trace.
* The difference in accuracy between "No mistake" and "Yes mistake" is most pronounced for "Direct (trace)".
### Interpretation
The data suggests that the accuracy of these prompting methods is highly dependent on the quality of the original trace. When the original trace is correct, the "Direct (trace)" method performs best. However, when the original trace contains a mistake, all methods suffer a significant drop in accuracy, with "Direct (trace)" being the most affected. This indicates that "Direct (trace)" is more sensitive to errors in the original trace compared to "Direct (step)" and "CoT (step)". The "CoT (step)" method appears to be the least effective overall, possibly indicating that the chain-of-thought approach is not well-suited for this particular task or dataset. The error bars indicate the variability in the data, suggesting that these accuracy values are estimates with a degree of uncertainty.