\n
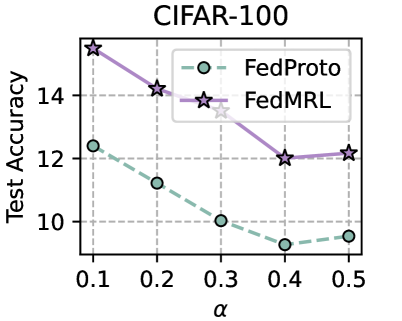
## Line Chart: CIFAR-100 Test Accuracy vs. Alpha
### Overview
This chart displays the relationship between test accuracy and the parameter alpha (α) for two different federated learning protocols: FedProto and FedMRL, on the CIFAR-100 dataset. The chart uses lines with markers to represent the data for each protocol.
### Components/Axes
* **Title:** CIFAR-100 (positioned at the top-center)
* **X-axis Label:** α (positioned at the bottom-center)
* **Y-axis Label:** Test Accuracy (positioned at the left-center)
* **Legend:** Located in the top-right corner.
* FedProto (represented by a dashed light-blue line with circular markers)
* FedMRL (represented by a solid purple line with star-shaped markers)
* **X-axis Markers:** 0.1, 0.2, 0.3, 0.4, 0.5
* **Y-axis Scale:** Ranges from approximately 9 to 16.
### Detailed Analysis
**FedProto (Light-Blue Dashed Line with Circles):**
The line slopes downward overall.
* At α = 0.1, Test Accuracy ≈ 12.1
* At α = 0.2, Test Accuracy ≈ 11.2
* At α = 0.3, Test Accuracy ≈ 10.1
* At α = 0.4, Test Accuracy ≈ 9.4
* At α = 0.5, Test Accuracy ≈ 9.6
**FedMRL (Purple Solid Line with Stars):**
The line initially slopes downward, then slightly upward.
* At α = 0.1, Test Accuracy ≈ 15.4
* At α = 0.2, Test Accuracy ≈ 14.3
* At α = 0.3, Test Accuracy ≈ 13.2
* At α = 0.4, Test Accuracy ≈ 12.1
* At α = 0.5, Test Accuracy ≈ 12.2
### Key Observations
* FedMRL consistently achieves higher test accuracy than FedProto across all values of α.
* FedProto's accuracy decreases steadily as α increases.
* FedMRL's accuracy decreases from α = 0.1 to α = 0.4, then shows a slight increase at α = 0.5.
* The difference in accuracy between the two protocols is most significant at lower values of α.
### Interpretation
The chart suggests that FedMRL is a more effective federated learning protocol than FedProto for the CIFAR-100 dataset, as it consistently yields higher test accuracy. The parameter α appears to have a negative impact on the performance of FedProto, while its effect on FedMRL is more complex, potentially indicating a sweet spot for α within the range tested. The slight increase in FedMRL accuracy at α = 0.5 could be due to the regularization effect of α, preventing overfitting. The data suggests that the choice of α is crucial for optimizing the performance of federated learning algorithms, and that different protocols may respond differently to changes in this parameter. The difference in performance between the two protocols could be attributed to differences in their underlying mechanisms for handling data heterogeneity or communication constraints.