## Bar Chart: Accuracy Comparison
### Overview
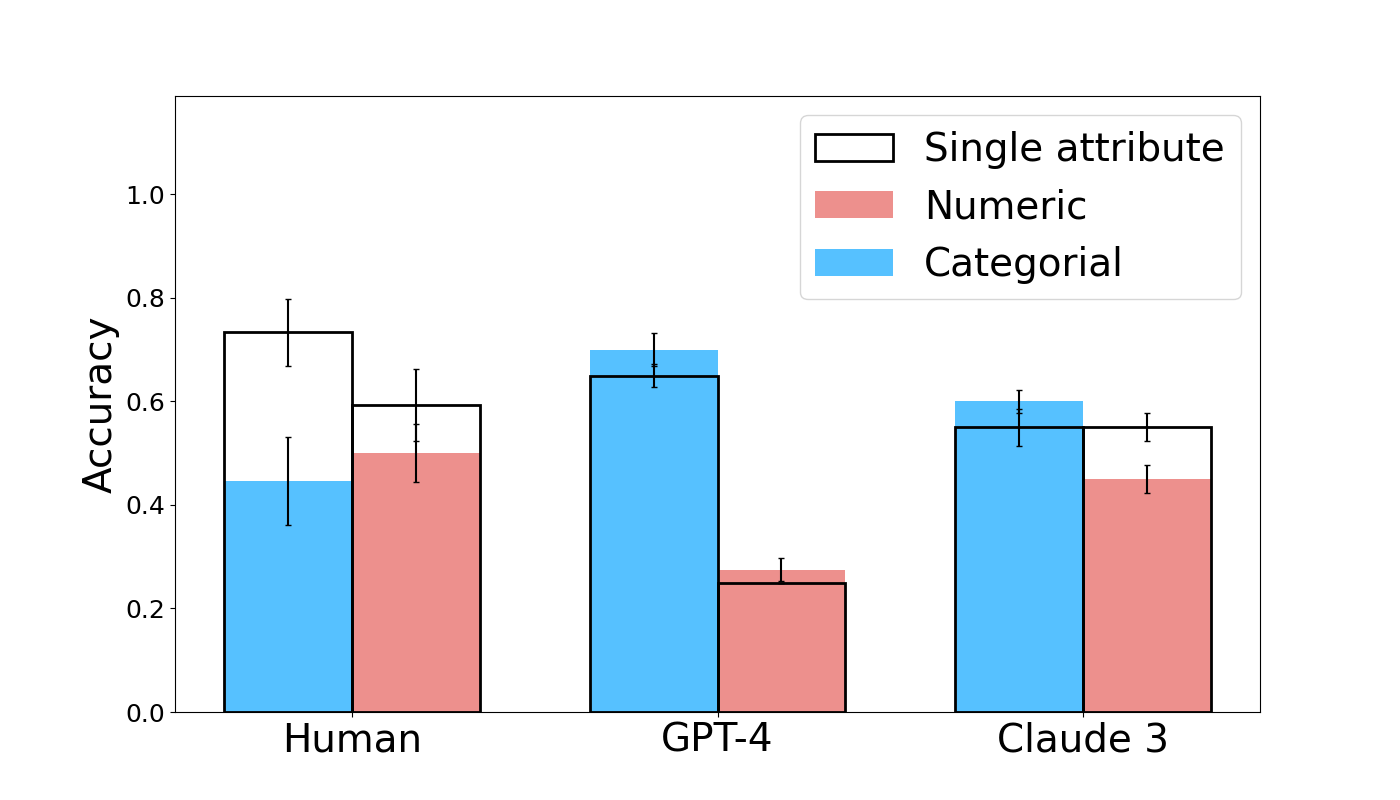
The image is a bar chart comparing the accuracy of humans, GPT-4, and Claude 3 across three attribute types: single attribute, numeric, and categorical. The chart displays accuracy on the y-axis, ranging from 0.0 to 1.0, and the three entities (Human, GPT-4, Claude 3) on the x-axis. Error bars are included on each bar.
### Components/Axes
* **Y-axis:** "Accuracy", ranging from 0.0 to 1.0 in increments of 0.2.
* **X-axis:** Categorical labels: "Human", "GPT-4", "Claude 3".
* **Legend:** Located in the top-right corner, it identifies the bar colors:
* White with black outline: "Single attribute"
* Light Red: "Numeric"
* Light Blue: "Categorial"
### Detailed Analysis
Here's a breakdown of the accuracy values for each entity and attribute type, including trend descriptions:
* **Human:**
* Single attribute: Accuracy is approximately 0.73, with an error bar extending from approximately 0.68 to 0.80.
* Numeric: Accuracy is approximately 0.50, with an error bar extending from approximately 0.45 to 0.58.
* Categorial: Accuracy is approximately 0.45, with an error bar extending from approximately 0.35 to 0.53.
* **GPT-4:**
* Single attribute: Accuracy is approximately 0.70, with an error bar extending from approximately 0.68 to 0.73.
* Numeric: Accuracy is approximately 0.25, with an error bar extending from approximately 0.23 to 0.28.
* Categorial: Accuracy is approximately 0.65, with an error bar extending from approximately 0.63 to 0.68.
* **Claude 3:**
* Single attribute: Accuracy is approximately 0.56, with an error bar extending from approximately 0.54 to 0.58.
* Numeric: Accuracy is approximately 0.45, with an error bar extending from approximately 0.43 to 0.48.
* Categorial: Accuracy is approximately 0.58, with an error bar extending from approximately 0.55 to 0.61.
### Key Observations
* For humans, single attribute accuracy is the highest, followed by numeric, and then categorical.
* GPT-4 shows the highest accuracy for single attribute and categorical, but significantly lower accuracy for numeric attributes.
* Claude 3 has relatively similar accuracy for all three attribute types, with categorical being slightly higher.
* GPT-4 has the largest difference in accuracy between attribute types.
### Interpretation
The bar chart illustrates the performance of humans, GPT-4, and Claude 3 on different types of attributes. Humans excel at single attribute tasks, while GPT-4 struggles with numeric attributes. Claude 3 demonstrates more consistent performance across all attribute types. The error bars provide an indication of the variability in the accuracy measurements. The data suggests that the models have different strengths and weaknesses depending on the nature of the task.