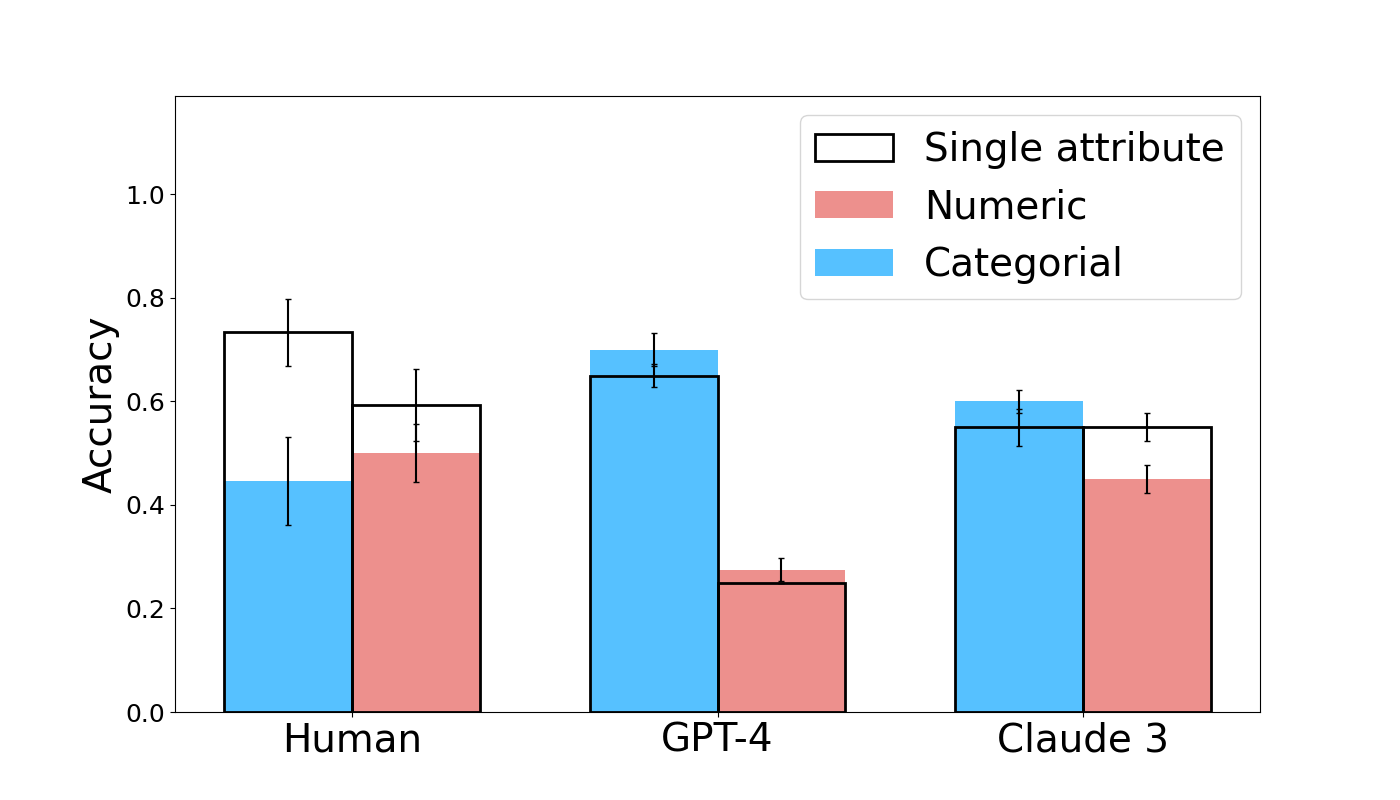
## Bar Chart: Model Accuracy Comparison Across Attribute Types
### Overview
The chart compares accuracy performance across three entities: Human, GPT-4, and Claude 3, evaluated on three attribute types: Single attribute (white), Numeric (red), and Categorical (blue). Accuracy is measured on a scale from 0.0 to 1.0, with error bars indicating variability.
### Components/Axes
- **X-axis**: Model (Human, GPT-4, Claude 3)
- **Y-axis**: Accuracy (0.0 to 1.0)
- **Legend**:
- White: Single attribute
- Red: Numeric
- Blue: Categorical
- **Error Bars**: Vertical lines atop each bar representing confidence intervals.
### Detailed Analysis
1. **Human**:
- Single attribute: ~0.75 (±0.05)
- Numeric: ~0.5 (±0.1)
- Categorical: ~0.45 (±0.1)
2. **GPT-4**:
- Single attribute: ~0.68 (±0.05)
- Numeric: ~0.25 (±0.05)
- Categorical: ~0.65 (±0.05)
3. **Claude 3**:
- Single attribute: ~0.55 (±0.05)
- Numeric: ~0.45 (±0.1)
- Categorical: ~0.60 (±0.05)
### Key Observations
- **Single attribute tasks** show the highest accuracy across all entities, with Human achieving the highest (~0.75).
- **Numeric tasks** are the most challenging, with GPT-4 performing significantly worse (~0.25) compared to Human (~0.5) and Claude 3 (~0.45).
- **Categorical tasks** demonstrate moderate performance, with GPT-4 outperforming Human (~0.65 vs. ~0.45) and Claude 3 (~0.60).
### Interpretation
The data suggests that:
1. **Single attribute tasks** are inherently easier, likely due to simpler pattern recognition requirements.
2. **Numeric tasks** pose significant challenges for AI models (GPT-4 and Claude 3), potentially due to the need for precise numerical reasoning or data interpretation.
3. **Categorical tasks** reveal a nuanced trend: GPT-4 outperforms humans, possibly indicating advanced pattern recognition in structured categorical data, while Claude 3 shows balanced performance.
4. Humans maintain an edge in Numeric tasks, suggesting domain-specific expertise or contextual understanding not fully captured by current AI models.
The error bars indicate variability in performance, with Numeric tasks showing the largest uncertainty (e.g., GPT-4's Numeric accuracy ±0.05). This chart highlights critical gaps in AI performance across different data types, emphasizing the need for specialized training in numeric reasoning.