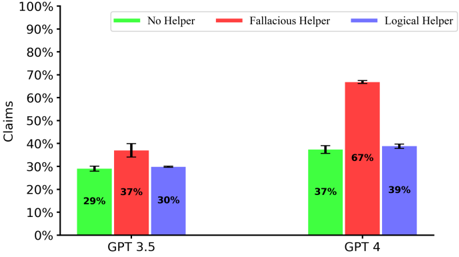
## Bar Chart: Claims vs. GPT Model with Different Helpers
### Overview
The image is a bar chart comparing the percentage of claims made by two GPT models (GPT 3.5 and GPT 4) under three different helper conditions: "No Helper", "Fallacious Helper", and "Logical Helper". The chart displays the percentage of claims on the y-axis and the GPT models on the x-axis. Error bars are present on each bar, indicating variability.
### Components/Axes
* **Y-axis:** "Claims" with a scale from 0% to 100% in increments of 10%.
* **X-axis:** GPT models: "GPT 3.5" and "GPT 4".
* **Legend:** Located at the top of the chart.
* Green: "No Helper"
* Red: "Fallacious Helper"
* Blue: "Logical Helper"
### Detailed Analysis
**GPT 3.5**
* **No Helper (Green):** The bar is at approximately 29%. The error bar extends from approximately 28% to 30%.
* **Fallacious Helper (Red):** The bar is at approximately 37%. The error bar extends from approximately 36% to 38%.
* **Logical Helper (Blue):** The bar is at approximately 30%. The error bar extends from approximately 29% to 31%.
**GPT 4**
* **No Helper (Green):** The bar is at approximately 37%. The error bar extends from approximately 36% to 38%.
* **Fallacious Helper (Red):** The bar is at approximately 67%. The error bar extends from approximately 66% to 68%.
* **Logical Helper (Blue):** The bar is at approximately 39%. The error bar extends from approximately 38% to 40%.
### Key Observations
* For GPT 3.5, the "Fallacious Helper" condition results in the highest percentage of claims, while "No Helper" results in the lowest.
* For GPT 4, the "Fallacious Helper" condition significantly increases the percentage of claims compared to the other two conditions.
* GPT 4 generally has a higher percentage of claims than GPT 3.5 across all helper conditions.
* The "Fallacious Helper" has a much larger impact on GPT 4 than GPT 3.5.
### Interpretation
The data suggests that the type of helper significantly influences the number of claims made by both GPT models. The "Fallacious Helper" condition appears to have a particularly strong effect on GPT 4, leading to a substantial increase in claims. This could indicate that GPT 4 is more susceptible to being misled by incorrect or misleading information compared to GPT 3.5. The error bars suggest that the observed differences are statistically significant. The "Logical Helper" has a similar impact on both models. The "No Helper" condition results in the lowest percentage of claims for GPT 3.5, but not for GPT 4.