\n
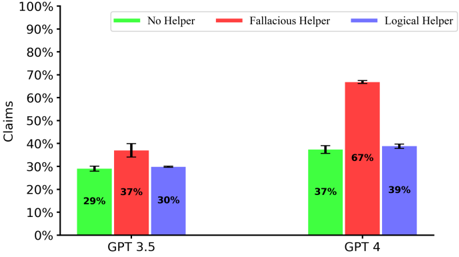
## Bar Chart: Claims with Different Helpers for GPT Models
### Overview
This bar chart compares the percentage of claims made by GPT 3.5 and GPT 4, with and without the assistance of "helpers". The helpers are categorized as "No Helper", "Fallacious Helper", and "Logical Helper". Error bars are included for each data point, indicating the uncertainty in the measurements.
### Components/Axes
* **X-axis:** GPT Model (GPT 3.5, GPT 4)
* **Y-axis:** Claims (Percentage, ranging from 0% to 100%)
* **Legend:**
* Green: No Helper
* Red: Fallacious Helper
* Blue: Logical Helper
* **Error Bars:** Represent the uncertainty around each data point.
### Detailed Analysis
The chart consists of six bars, grouped by GPT model. Each group has three bars representing the three helper types.
**GPT 3.5:**
* **No Helper (Green):** The bar reaches approximately 29% with an error bar extending from roughly 25% to 33%.
* **Fallacious Helper (Red):** The bar reaches approximately 37% with an error bar extending from roughly 33% to 41%.
* **Logical Helper (Blue):** The bar reaches approximately 30% with an error bar extending from roughly 26% to 34%.
**GPT 4:**
* **No Helper (Green):** The bar reaches approximately 37% with an error bar extending from roughly 33% to 41%.
* **Fallacious Helper (Red):** The bar reaches approximately 67% with an error bar extending from roughly 63% to 71%.
* **Logical Helper (Blue):** The bar reaches approximately 39% with an error bar extending from roughly 35% to 43%.
### Key Observations
* The "Fallacious Helper" significantly increases the percentage of claims made by GPT 4 compared to the other conditions.
* GPT 4 generally makes more claims than GPT 3.5 across all helper types.
* The "Logical Helper" has a relatively consistent effect on claim rates for both GPT 3.5 and GPT 4.
* The error bars suggest a moderate degree of uncertainty in the measurements.
### Interpretation
The data suggests that the type of assistance provided to a large language model (LLM) can significantly impact its tendency to make claims. Specifically, a "Fallacious Helper" dramatically increases the claim rate in GPT 4. This could indicate that GPT 4 is more susceptible to being led to make claims when presented with flawed reasoning or misleading information. The relatively small effect of the "Logical Helper" suggests that providing sound reasoning does not necessarily increase claim rates to the same extent.
The difference between GPT 3.5 and GPT 4 suggests that the newer model is more responsive to external influences, both positive (logical help) and negative (fallacious help). This could be due to changes in the model's architecture, training data, or internal mechanisms for evaluating information.
The error bars indicate that these observations are not definitive, and further research with larger sample sizes may be needed to confirm these trends. The use of "Fallacious Helper" is particularly concerning, as it highlights a potential vulnerability of LLMs to manipulation and the generation of unsupported claims.