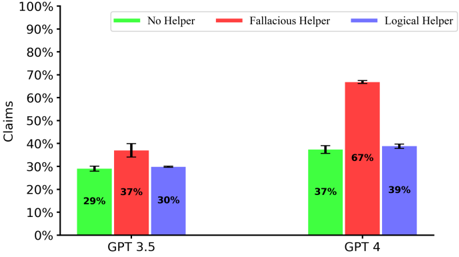
## Bar Chart: Claims Percentage by AI Model and Helper Type
### Overview
This is a grouped bar chart comparing the percentage of claims generated by two AI models (GPT 3.5 and GPT 4) under three experimental conditions: No Helper, Fallacious Helper, and Logical Helper. The chart visually demonstrates how the type of helper influences the models' output.
### Components/Axes
* **Chart Type:** Grouped bar chart with error bars.
* **Y-Axis:** Labeled "Claims". Scale ranges from 0% to 100% in increments of 10%.
* **X-Axis:** Two primary categories representing the AI models: "GPT 3.5" (left group) and "GPT 4" (right group).
* **Legend:** Located at the top center of the chart.
* Green bar: "No Helper"
* Red bar: "Fallacious Helper"
* Blue bar: "Logical Helper"
* **Data Labels:** Percentage values are printed directly on each bar.
* **Error Bars:** Small vertical lines are present atop each bar, indicating variability or confidence intervals (exact values not specified).
### Detailed Analysis
**Data Points Extracted:**
| Model | Helper Type | Claims (%) |
| :-------- | :---------------- | :--------- |
| GPT 3.5 | No Helper (Green) | 29% |
| GPT 3.5 | Fallacious Helper (Red) | 37% |
| GPT 3.5 | Logical Helper (Blue) | 30% |
| GPT 4 | No Helper (Green) | 37% |
| GPT 4 | Fallacious Helper (Red) | 67% |
| GPT 4 | Logical Helper (Blue) | 39% |
**Trend Verification:**
* **GPT 3.5 Group:** The "Fallacious Helper" bar (red, 37%) is the tallest, followed by "Logical Helper" (blue, 30%), and then "No Helper" (green, 29%). The trend shows a moderate increase in claims when any helper is present, with the fallacious helper having the largest effect.
* **GPT 4 Group:** The "Fallacious Helper" bar (red, 67%) is dramatically taller than the other two. "Logical Helper" (blue, 39%) and "No Helper" (green, 37%) are nearly equal in height. The trend shows a massive spike in claims specifically with the fallacious helper.
* **Cross-Model Comparison:** All three conditions show a higher percentage of claims for GPT 4 compared to GPT 3.5. The increase is most extreme for the "Fallacious Helper" condition (+30 percentage points).
### Key Observations
1. **Dominant Effect of Fallacious Helper on GPT 4:** The most striking feature is the red bar for GPT 4, which is the tallest element in the chart at 67%. This is nearly double the value for the same condition in GPT 3.5.
2. **Minimal Impact of Logical Helper:** For both models, the "Logical Helper" condition results in a claim percentage very close to the "No Helper" baseline (GPT 3.5: 30% vs 29%; GPT 4: 39% vs 37%).
3. **Baseline Increase from GPT 3.5 to GPT 4:** Even without any helper (green bars), GPT 4 (37%) produces a higher percentage of claims than GPT 3.5 (29%).
### Interpretation
The data suggests a significant and model-dependent interaction between the type of辅助信息 (helper information) and the propensity of Large Language Models (LLMs) to generate claims.
* **Susceptibility to Misinformation:** The "Fallacious Helper" condition likely provides misleading or incorrect information. The chart indicates that GPT 4 is far more susceptible to this type of input, leading to a dramatic increase in claim generation. This could imply that more advanced models, while more capable, may also be more confidently influenced by flawed premises.
* **Robustness to Logical Guidance:** The "Logical Helper" condition, presumably providing sound reasoning or facts, does not significantly increase claim output over the baseline. This suggests that providing correct information does not inherently make the models more "claim-happy"; their claim generation is more sensitive to the *nature* of the input (fallacious vs. logical) than to the mere presence of辅助信息.
* **Model Evolution:** The increase in the "No Helper" baseline from GPT 3.5 to GPT 4 suggests an inherent change in the models' default behavior, possibly due to differences in training data, scale, or alignment, leading GPT 4 to make more assertions unprompted.
**In summary, the chart provides evidence that the influence of helper information on LLM output is not uniform. Fallacious information acts as a strong catalyst for claim generation, especially in the more advanced GPT 4 model, while logical information has a negligible effect compared to no helper at all.**