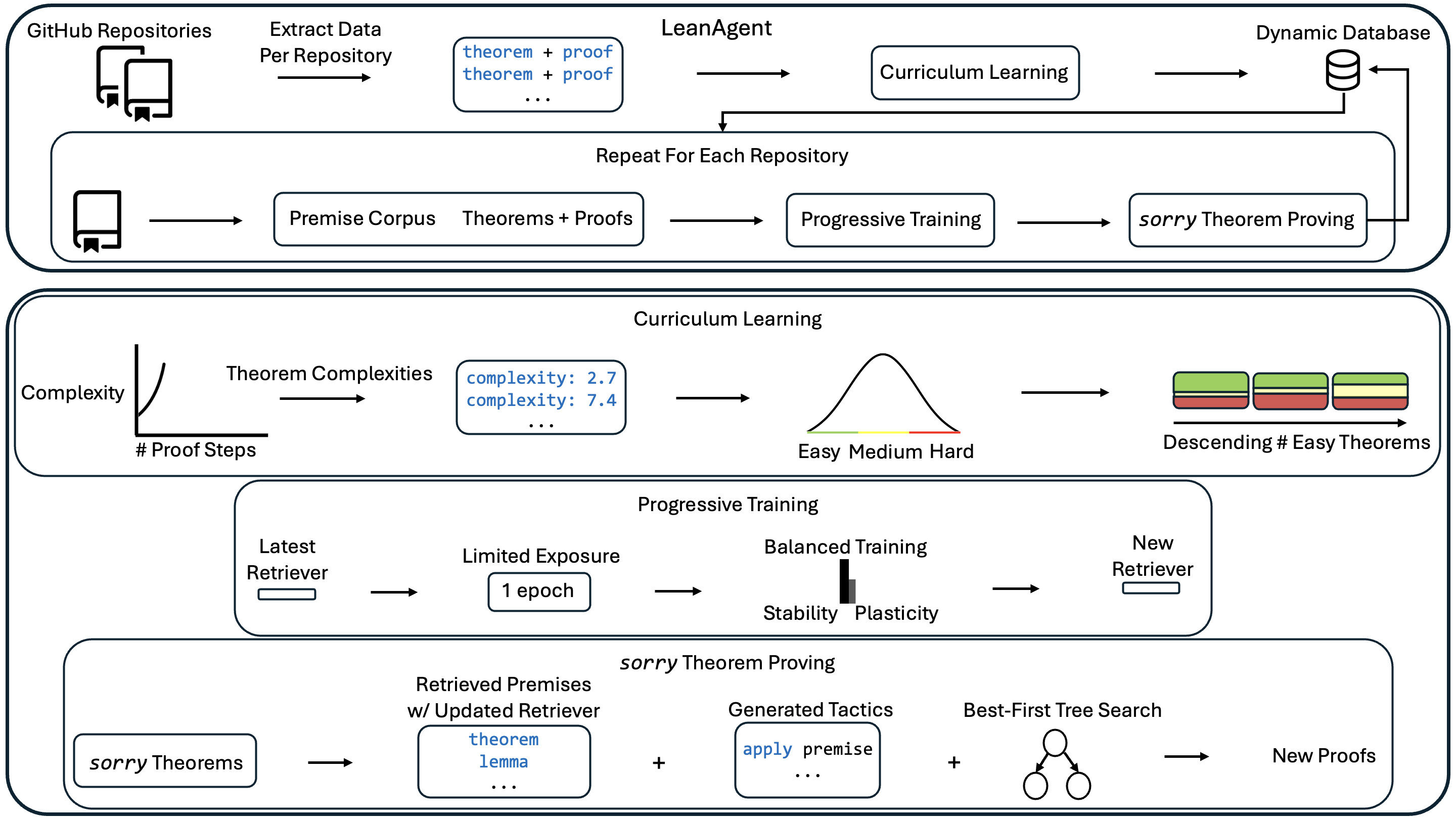
## Diagram: LeanAgent Workflow
### Overview
The image is a diagram illustrating the workflow of LeanAgent, a system for automated theorem proving. The diagram is divided into several stages, including data extraction from GitHub repositories, curriculum learning, progressive training, and theorem proving. The workflow involves iterative processes and feedback loops.
### Components/Axes
* **GitHub Repositories:** Represents the source of theorem and proof data.
* **Extract Data Per Repository:** Process of extracting theorem and proof data from GitHub repositories.
* **LeanAgent:** The overall system for automated theorem proving.
* **Dynamic Database:** A database used to store and retrieve theorems and proofs.
* **Curriculum Learning:** A stage involving learning curricula.
* **Repeat For Each Repository:** Indicates an iterative process.
* **Premise Corpus Theorems + Proofs:** A collection of premises, theorems, and proofs.
* **Progressive Training:** A training stage.
* **sorry Theorem Proving:** The final stage of theorem proving.
* **Complexity vs. # Proof Steps:** A graph showing the relationship between theorem complexity and the number of proof steps. The y-axis is labeled "Complexity" and the x-axis is labeled "# Proof Steps". The graph shows a curve that increases rapidly.
* **Theorem Complexities:** Indicates the complexity of theorems. Examples given are "complexity: 2.7" and "complexity: 7.4".
* **Easy Medium Hard:** Labels indicating the difficulty levels in curriculum learning. These are associated with a bell curve.
* **Descending # Easy Theorems:** Indicates a descending order of easy theorems. The blocks are colored green, yellow, and red.
* **Latest Retriever:** The most recent retriever model.
* **Limited Exposure:** A stage with limited exposure, indicated as "1 epoch".
* **Balanced Training:** A training stage with balanced stability and plasticity.
* **Stability Plasticity:** Labels indicating the balance between stability and plasticity.
* **New Retriever:** The updated retriever model.
* **sorry Theorems:** Theorems that need to be proven.
* **Retrieved Premises w/ Updated Retriever:** Premises retrieved using an updated retriever. Examples given are "theorem" and "lemma".
* **Generated Tactics:** Tactics generated for theorem proving. Example given is "apply premise".
* **Best-First Tree Search:** A search algorithm used for theorem proving.
* **New Proofs:** The resulting proofs.
### Detailed Analysis
* **Data Extraction:** The process starts with extracting data from GitHub repositories. The extracted data includes theorems and proofs.
* **LeanAgent Core:** The extracted data is fed into the LeanAgent system.
* **Curriculum Learning Loop:** The system uses curriculum learning, which involves a dynamic database. The process is repeated for each repository.
* **Complexity Graph:** The graph shows that as the number of proof steps increases, the complexity of the theorem also increases.
* **Curriculum Stages:** The curriculum learning stage involves easy, medium, and hard difficulty levels. The number of easy theorems decreases.
* **Progressive Training Stages:** The progressive training stage involves a latest retriever, limited exposure (1 epoch), and balanced training.
* **Theorem Proving Stages:** The theorem proving stage involves retrieved premises, generated tactics, and a best-first tree search.
### Key Observations
* The diagram illustrates a cyclical workflow, with feedback loops between different stages.
* The curriculum learning stage involves a progression from easy to hard difficulty levels.
* The progressive training stage aims to balance stability and plasticity.
* The theorem proving stage uses a best-first tree search algorithm.
### Interpretation
The diagram provides a high-level overview of the LeanAgent workflow for automated theorem proving. The system leverages data from GitHub repositories, employs curriculum learning and progressive training techniques, and uses a best-first tree search algorithm for theorem proving. The iterative nature of the workflow suggests a continuous learning and improvement process. The balance between stability and plasticity in the progressive training stage is crucial for adapting to new data while maintaining existing knowledge. The complexity graph indicates that more complex theorems require more proof steps.