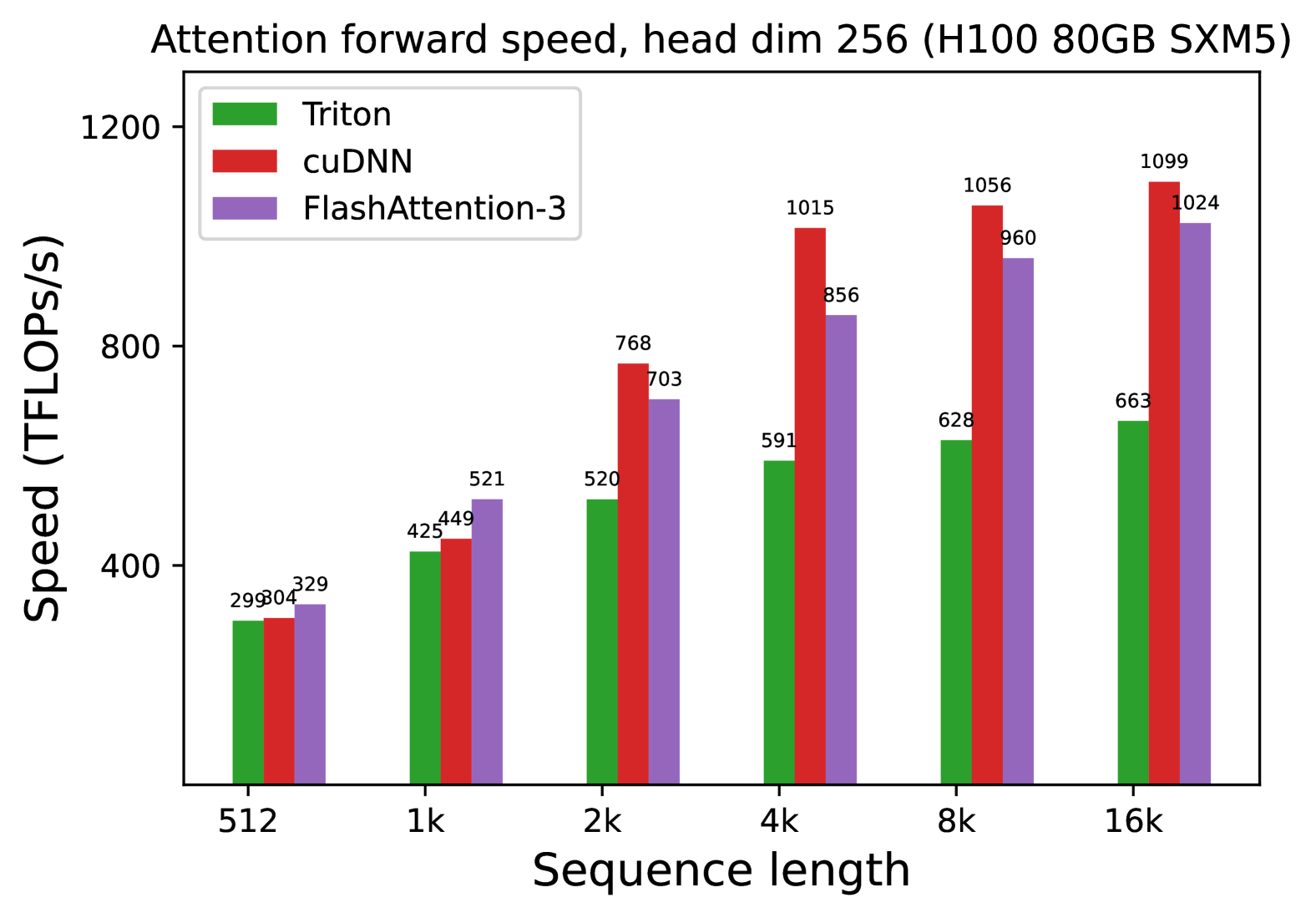
# Technical Analysis: Attention Forward Speed (Head Dim 256, H100 80GB SXM5)
## Chart Title
**Attention forward speed, head dim 256 (H100 80GB SXM5)**
## Axis Labels
- **X-axis**: Sequence length (categories: 512, 1k, 2k, 4k, 8k, 16k)
- **Y-axis**: Speed (TFLOPs/s)
## Legend
- **Triton**: Green
- **cuDNN**: Red
- **FlashAttention-3**: Purple
## Data Points by Sequence Length
| Sequence Length | Triton (TFLOPs/s) | cuDNN (TFLOPs/s) | FlashAttention-3 (TFLOPs/s) |
|-----------------|--------------------|-------------------|------------------------------|
| 512 | 299 | 304 | 329 |
| 1k | 425 | 449 | 521 |
| 2k | 520 | 768 | 703 |
| 4k | 591 | 1015 | 856 |
| 8k | 628 | 1056 | 960 |
| 16k | 663 | 1099 | 1024 |
## Key Observations
1. **Performance Trends**:
- **cuDNN** consistently outperforms other methods across all sequence lengths.
- **FlashAttention-3** shows significant improvement over Triton, particularly at longer sequence lengths (e.g., 16k: 1024 TFLOPs/s vs. Triton's 663 TFLOPs/s).
- **Triton** exhibits the lowest performance but scales linearly with sequence length.
2. **Hardware Context**:
- All measurements were conducted on **H100 80GB SXM5** GPUs.
3. **Method Comparison**:
- cuDNN maintains a ~30-40% speed advantage over FlashAttention-3 at 16k sequence length.
- FlashAttention-3 outperforms Triton by ~2.5x at 16k sequence length.
## Notes
- The chart uses grouped bar visualization to compare three attention mechanisms.
- All values are explicitly labeled on the bars for direct verification.
- The legend is positioned in the top-left corner for clarity.