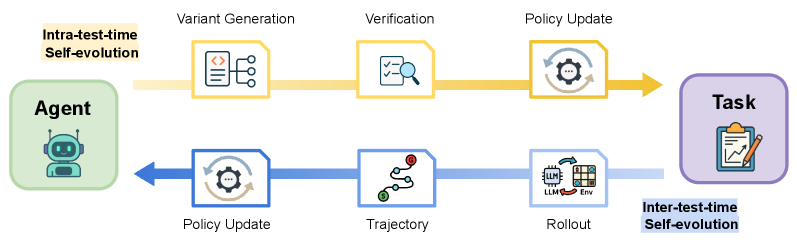
## Diagram: Agent Self-Evolution Process Flow
### Overview
The image is a conceptual flowchart illustrating two complementary processes for an AI agent's self-improvement: "Intra-test-time Self-evolution" and "Inter-test-time Self-evolution." The diagram depicts a cyclical flow between an "Agent" and a "Task," with distinct pathways for evolution during a task and between tasks.
### Components/Axes
The diagram is structured with two primary entities and two main process flows.
**Primary Entities:**
1. **Agent** (Left side): Represented by a green rounded rectangle containing a robot icon.
2. **Task** (Right side): Represented by a purple rounded rectangle containing a clipboard with a pencil icon.
**Process Flows:**
1. **Top Path (Yellow):** Labeled **"Intra-test-time Self-evolution"**. This flow moves from the Agent to the Task.
2. **Bottom Path (Blue):** Labeled **"Inter-test-time Self-evolution"**. This flow moves from the Task back to the Agent.
**Detailed Components (in flow order):**
**A. Intra-test-time Self-evolution (Yellow Path, Left to Right):**
1. **Variant Generation:** Icon shows a document with code symbols (`</>`) and branching arrows. Positioned immediately right of the Agent.
2. **Verification:** Icon shows a document with a magnifying glass over it. Positioned to the right of Variant Generation.
3. **Policy Update:** Icon shows a gear with circular arrows around it. Positioned to the right of Verification, just before the Task.
**B. Inter-test-time Self-evolution (Blue Path, Right to Left):**
1. **Rollout:** Icon shows a chip labeled "LLM" connected to a grid labeled "Env" (Environment). Positioned immediately left of the Task.
2. **Trajectory:** Icon shows a winding path with a start point (green circle) and an end point (red pin). Positioned to the left of Rollout.
3. **Policy Update:** Icon is identical to the one in the yellow path (gear with circular arrows). Positioned to the left of Trajectory, just before the Agent.
### Detailed Analysis
The diagram presents a closed-loop system for agent improvement.
* **Spatial Grounding:** The "Agent" is anchored on the far left, and the "Task" on the far right. The two evolution processes are visually separated, with the "Intra-test-time" process flowing above the central axis and the "Inter-test-time" process flowing below it.
* **Flow Direction:** Arrows clearly indicate directionality. The yellow path flows left-to-right (Agent -> Task). The blue path flows right-to-left (Task -> Agent), completing the cycle.
* **Component Isolation:**
* **Header/Labels:** The titles for the two self-evolution types are placed near their respective paths.
* **Main Process:** The core of the diagram consists of the six process steps (three per path) connected by arrows.
* **Footer/Entities:** The Agent and Task boxes serve as the start and end points for the respective flows.
### Key Observations
1. **Symmetry and Repetition:** The "Policy Update" step appears in both evolution cycles, suggesting it is a critical, recurring phase for integrating learnings.
2. **Distinct Phases:** The processes are clearly divided into actions taken *during* an active task (Intra-test-time: generating variants, verifying them) and actions taken *between* task executions (Inter-test-time: running rollouts, analyzing trajectories).
3. **Iconography:** Each step uses a distinct, metaphorical icon to represent its function (e.g., magnifying glass for verification, winding path for trajectory).
### Interpretation
This diagram illustrates a sophisticated framework for continuous agent learning, likely in the context of large language models (LLMs) or reinforcement learning.
* **What it demonstrates:** It proposes a dual-loop improvement system. The **Intra-test-time loop** allows the agent to experiment and adapt *while* performing a specific task, perhaps by generating and testing different solution variants. The **Inter-test-time loop** represents a more reflective, offline learning phase where the agent analyzes its past performance (rollouts and trajectories) to update its core policy before the next task.
* **Relationship between elements:** The Agent is both the initiator and the beneficiary of the cycle. It acts on the Task, and the results from the Task feed back into a learning process that refines the Agent itself. The "Policy Update" is the crucial bridge that turns experience into improved capability.
* **Underlying concept:** The model suggests that optimal agent performance requires both rapid, in-context adaptation (intra-test) and deliberate, post-hoc analysis and policy refinement (inter-test). This mirrors concepts in machine learning like online learning versus batch learning, or exploration versus exploitation. The goal is a system that doesn't just complete tasks but evolves its fundamental approach to completing them more effectively over time.