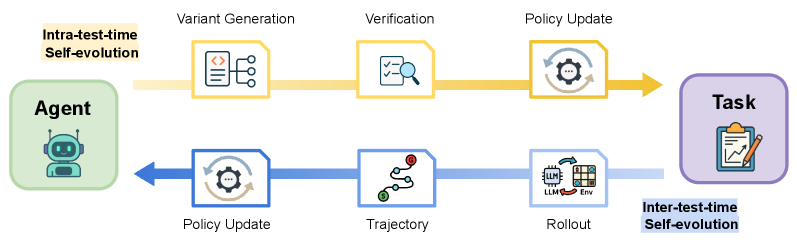
## Flowchart: Agent-Task Interaction with Self-Evolution Processes
### Overview
The flowchart illustrates a two-stage self-evolution process for an AI agent interacting with a task environment. It contrasts **Intra-test-time Self-evolution** (orange) and **Inter-test-time Self-evolution** (blue), showing how the agent iteratively improves its policy through variant generation, verification, and rollout. The Agent (left) initiates the process, leading to a Task (right) via feedback loops.
---
### Components/Axes
- **Agent**: Represented by a robot icon (top-left), initiates the process.
- **Task**: Depicted as a clipboard with a pencil (bottom-right), the end goal.
- **Intra-test-time Self-evolution** (orange):
- **Variant Generation**: Code snippet with branching paths.
- **Verification**: Checklist with magnifying glass.
- **Policy Update**: Gear icon with circular arrows.
- **Inter-test-time Self-evolution** (blue):
- **Policy Update**: Gear icon (shared with intra-test-time).
- **Trajectory**: Path with red dot.
- **Rollout**: Grid with "LLM" and "Env" labels.
- **Arrows**: Connect components in sequential flow (left-to-right, top-to-bottom).
---
### Detailed Analysis
1. **Intra-test-time Self-evolution** (orange):
- **Variant Generation**: Generates diverse policy variants (code snippet with branching logic).
- **Verification**: Validates variants against criteria (checklist + magnifying glass).
- **Policy Update**: Updates the agent's policy based on verification results (gear icon).
2. **Inter-test-time Self-evolution** (blue):
- **Policy Update**: Applies updated policy to the environment (shared step with intra-test-time).
- **Trajectory**: Simulates agent behavior in the environment (path with red dot).
- **Rollout**: Executes policy in the environment, incorporating LLM and environmental feedback (grid icon).
3. **Flow Direction**:
- Arrows connect Agent → Variant Generation → Verification → Policy Update → Task (intra-test-time).
- Inter-test-time loops back from Policy Update → Trajectory → Rollout → Task, then re-enters the intra-test-time cycle.
---
### Key Observations
- **Color Coding**: Orange (intra-test-time) and blue (inter-test-time) visually separate the two evolution phases.
- **Feedback Loops**: Arrows create cyclical dependencies, emphasizing iterative improvement.
- **Shared Step**: "Policy Update" appears in both processes, acting as a bridge between them.
- **Environment Interaction**: "Rollout" explicitly involves the environment ("Env") and LLM, suggesting real-world testing.
---
### Interpretation
The diagram demonstrates a hybrid self-evolution framework where the agent:
1. **Intra-test-time**: Continuously refines its policy during testing via variant generation and verification, ensuring robustness before deployment.
2. **Inter-test-time**: Applies the updated policy in the environment, collects trajectory data, and uses rollout feedback to further evolve the policy. This creates a closed-loop system where real-world interactions inform future improvements.
The separation of intra- and inter-test-time processes highlights a balance between controlled testing (intra) and adaptive learning from real-world deployment (inter). The shared "Policy Update" step ensures coherence between the two phases, while distinct icons (gear vs. grid) clarify their unique roles. The Agent’s central position underscores its autonomy in driving the evolution process toward the Task.