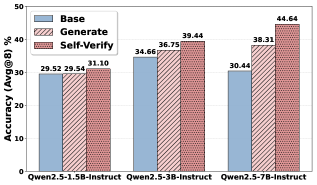
## Bar Chart: Model Accuracy Comparison (Avg@8)
### Overview
The chart compares the accuracy of three models (Qwen2.5-1.5B-Instruct, Qwen2.5-3B-Instruct, Qwen2.5-7B-Instruct) across three methods: Base, Generate, and Self-Verify. Accuracy is measured as Avg@8 (average accuracy at 8% threshold) in percentage terms.
### Components/Axes
- **X-axis**: Model variants (Qwen2.5-1.5B-Instruct, Qwen2.5-3B-Instruct, Qwen2.5-7B-Instruct)
- **Y-axis**: Accuracy (Avg@8) % (0–50% scale)
- **Legend**:
- Blue: Base
- Striped: Generate
- Dotted: Self-Verify
- **Bar Colors**:
- Base (blue), Generate (striped), Self-Verify (dotted) for each model group.
### Detailed Analysis
1. **Qwen2.5-1.5B-Instruct**:
- Base: 29.52%
- Generate: 29.54%
- Self-Verify: 31.10%
- *Trend*: Self-Verify shows a slight improvement over Base/Generate.
2. **Qwen2.5-3B-Instruct**:
- Base: 34.66%
- Generate: 36.75%
- Self-Verify: 39.44%
- *Trend*: Generate outperforms Base by ~2.09%, while Self-Verify adds ~2.69% over Generate.
3. **Qwen2.5-7B-Instruct**:
- Base: 30.44%
- Generate: 38.31%
- Self-Verify: 44.64%
- *Trend*: Generate improves Base by ~7.87%, and Self-Verify adds ~6.33% over Generate.
### Key Observations
- **Self-Verify Dominance**: Self-Verify consistently achieves the highest accuracy across all models, with the largest gap in the 7B model (44.64%).
- **Model Size Correlation**: Larger models (7B) outperform smaller ones (1.5B, 3B) in all methods, with the 7B model showing the most significant Self-Verify advantage.
- **Generate vs. Base**: Generate improves Base accuracy in all cases, but the improvement diminishes in larger models (e.g., 7B: +7.87% vs. 1.5B: +0.02%).
### Interpretation
The data demonstrates that **Self-Verify** is the most effective method for enhancing accuracy, particularly in larger models. The 7B model’s Self-Verify accuracy (44.64%) exceeds the Base accuracy of smaller models by ~15%, highlighting scalability benefits. The Generate method provides incremental gains over Base, but Self-Verify’s compounding effect (e.g., +6.33% over Generate in 7B) suggests it introduces critical validation mechanisms. This implies that self-verification is a key architectural component for optimizing model performance, especially as model size increases.