TECHNICAL ASSET FINGERPRINT
f4b95a78fc244fb926ef328b
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
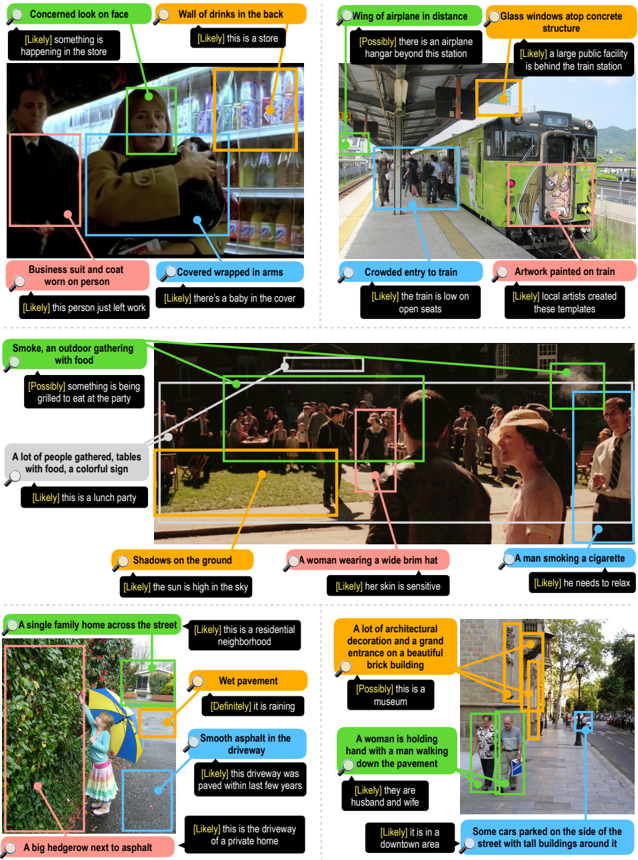
## Image Analysis: Scene Annotations
### Overview
The image presents a collage of six different scenes, each annotated with bounding boxes and descriptive text. The annotations provide details about the objects, people, and activities within each scene, along with likelihood assessments.
### Components/Axes
Each scene is analyzed with the following elements:
* **Scene Image:** A photograph or still image capturing a specific moment or location.
* **Bounding Boxes:** Rectangular outlines highlighting specific objects or regions of interest within the scene. Each box is associated with a description.
* **Descriptive Text:** Short phrases or sentences providing information about the content within the bounding box.
* **Likelihood Assessment:** A bracketed statement (e.g., "[Likely]", "[Possibly]", "[Definitely]") indicating the confidence level associated with the description.
* **Color-Coded Annotations:** Each annotation type (object, person, activity) is associated with a specific color for easy identification.
### Detailed Analysis or Content Details
Here's a breakdown of each scene:
1. **Scene 1 (Top-Left):**
* **Concerned look on face (Green):** A person with a concerned expression. [Likely] something is happening in the store.
* **Wall of drinks in the back (Orange):** A shelf stocked with beverages. [Likely] this is a store.
* **Business suit and coat worn on person (Pink):** A person wearing formal attire. [Likely] this person just left work.
* **Covered wrapped in arms (Blue):** A person holding something wrapped in their arms. [Likely] there's a baby in the cover.
2. **Scene 2 (Top-Right):**
* **Wing of airplane in distance (Black):** A distant airplane wing. [Possibly] there is an airplane hangar beyond this station.
* **Glass windows atop concrete structure (Orange):** A building with glass windows. [Likely] a large public facility is behind the train station.
* **Crowded entry to train (Blue):** People boarding a train. [Likely] the train is low on open seats.
* **Artwork painted on train (Pink):** Graffiti or artwork on the side of the train. [Likely] local artists created these templates.
3. **Scene 3 (Middle):**
* **Smoke, an outdoor gathering with food (Green):** Smoke rising in an outdoor setting with people and food. [Possibly] something is being grilled to eat at the party.
* **A lot of people gathered, tables with food, a colorful sign (Orange):** A gathering of people around tables with food. [Likely] this is a lunch party.
* **Shadows on the ground (Orange):** Shadows cast on the ground. [Likely] the sun is high in the sky.
* **A woman wearing a wide brim hat (Pink):** A woman wearing a hat. [Likely] her skin is sensitive.
* **A man smoking a cigarette (Blue):** A man smoking. [Likely] he needs to relax.
4. **Scene 4 (Bottom-Left):**
* **A single family home across the street (Green):** A house across the street. [Likely] this is a residential neighborhood.
* **Wet pavement (Orange):** Pavement that appears wet. [Definitely] it is raining.
* **Smooth asphalt in the driveway (Blue):** A driveway made of asphalt. [Likely] this driveway was paved within last few years.
* **A big hedgerow next to asphalt (Pink):** A large hedge next to the asphalt. [Likely] this is the driveway of a private home.
5. **Scene 5 (Bottom-Right):**
* **A lot of architectural decoration and a grand entrance on a beautiful brick building (Orange):** A building with ornate architectural details. [Possibly] this is a museum.
* **A woman is holding hand with a man walking down the pavement (Green):** A couple walking hand-in-hand. [Likely] they are husband and wife.
* **Some cars parked on the side of the street with tall buildings around it (Blue):** Cars parked on a street with tall buildings. [Likely] it is in a downtown area.
### Key Observations
* The annotations provide contextual information about the scenes, going beyond simple object detection.
* The likelihood assessments add a layer of uncertainty, acknowledging that the descriptions are interpretations rather than definitive statements.
* The color-coding helps to quickly identify the different types of annotations.
### Interpretation
The image demonstrates a scene understanding task, where the goal is to analyze visual content and provide meaningful descriptions. The annotations combine object detection with contextual reasoning to infer activities, relationships, and environmental conditions. The use of likelihood assessments acknowledges the inherent ambiguity in visual interpretation. The variety of scenes showcases the model's ability to generalize across different environments and situations.
DECODING INTELLIGENCE...
EXPERT: gemini-3.1-flash-lite-preview-free VERSION 1
RUNTIME: google-free/gemini-3.1-flash-lite-preview
INTEL_VERIFIED
## Annotated Image: Visual Scene Inference Analysis
### Overview
The image is a composite of five distinct photographic scenes, each overlaid with bounding boxes and text labels. The annotations function as a "scene understanding" demonstration, where specific visual elements are identified (e.g., "Wet pavement") and then paired with a logical inference or deduction (e.g., "[Definitely] it is raining"). The image serves as an example of how computer vision systems attempt to derive context and situational meaning from raw visual data.
### Components/Axes
The image is divided into four primary quadrants, with a large central scene spanning the middle.
* **Top-Left:** A woman in a store.
* **Top-Right:** A train station platform.
* **Center:** An outdoor social gathering.
* **Bottom-Left:** A child in a driveway.
* **Bottom-Right:** A street scene with pedestrians.
### Detailed Analysis
#### 1. Top-Left: Store Scene
* **Green Box (Top-Left):** "Concerned look on face" -> *[Likely] something is happening in the store*
* **Orange Box (Top-Right):** "Wall of drinks in the back" -> *[Likely] this is a store*
* **Pink Box (Bottom-Left):** "Business suit and coat worn on person" -> *[Likely] this person just left work*
* **Blue Box (Bottom-Center):** "Covered wrapped in arms" -> *[Likely] there's a baby in the cover*
#### 2. Top-Right: Train Station Scene
* **Green Box (Far Left):** "Wing of airplane in distance" -> *[Possibly] there is an airplane hangar beyond this station*
* **Orange Box (Top-Right):** "Glass windows atop concrete structure" -> *[Likely] a large public facility is behind the train station*
* **Blue Box (Center):** "Crowded entry to train" -> *[Likely] the train is low on open seats*
* **Pink Box (Bottom-Right):** "Artwork painted on train" -> *[Likely] local artists created these templates*
#### 3. Center: Outdoor Party Scene
* **Green Box (Top-Left/Center):** "Smoke, an outdoor gathering with food" -> *[Possibly] something is being grilled to eat at the party*
* **White Box (Top-Center):** "A lot of people gathered, tables with food, a colorful sign" -> *[Likely] this is a lunch party*
* **Orange Box (Bottom-Left):** "Shadows on the ground" -> *[Likely] the sun is high in the sky*
* **Pink Box (Center):** "A woman wearing a wide brim hat" -> *[Likely] her skin is sensitive*
* **Blue Box (Bottom-Right):** "A man smoking a cigarette" -> *[Likely] he needs to relax*
#### 4. Bottom-Left: Driveway Scene
* **Pink Box (Left):** "A big hedgerow next to asphalt"
* **Green Box (Top-Center):** "A single family home across the street" -> *[Likely] this is a residential neighborhood*
* **Orange Box (Center):** "Wet pavement" -> *[Definitely] it is raining*
* **Blue Box (Bottom-Center):** "Smooth asphalt in the driveway" -> *[Likely] this driveway was paved within last few years*
* **Black Box (Bottom-Right):** *[Likely] this is the driveway of a private home*
#### 5. Bottom-Right: Street Scene
* **Orange Box (Top-Left):** "A lot of architectural decoration and a grand entrance on a brick building" -> *[Possibly] this is a museum*
* **Green Box (Bottom-Left):** "A woman is holding hand with a man walking down the pavement" -> *[Likely] they are husband and wife*
* **Blue Box (Bottom-Right):** "Some cars parked on the side of the street with tall buildings around it" -> *[Likely] it is in a downtown area*
### Key Observations
* **Inference Hierarchy:** The annotations utilize a confidence-based hierarchy: "[Definitely]" for physical observations (e.g., wet pavement), "[Likely]" for high-probability social or situational inferences, and "[Possibly]" for speculative interpretations.
* **Stereotyping/Social Norms:** The inferences rely heavily on common social assumptions (e.g., holding hands implies a married couple; a woman in a hat implies sensitive skin; a man smoking implies a need to relax).
* **Spatial Grounding:** The bounding boxes are generally accurate in their placement, effectively isolating the subject matter being described.
### Interpretation
This image demonstrates the application of "Semantic Scene Understanding." It illustrates how AI models are trained to move beyond simple object detection (identifying a "man" or "building") to higher-level reasoning.
The data suggests a system attempting to "read" human behavior and environmental context. However, the inferences are often subjective. For example, while "wet pavement" is an objective fact, the inference that a man smoking "needs to relax" is a subjective psychological projection. This highlights the limitations of current AI in distinguishing between objective environmental facts and subjective human motivations. The document serves as a case study in how AI interprets visual input through the lens of learned social patterns.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Annotated Photographs: Contextual Observations and Inferences
### Overview
The image comprises four annotated photographs, each depicting distinct scenes with overlaid text boxes, magnifying glass icons, and labels. These annotations provide contextual observations, inferences, and speculative conclusions about the subjects, environments, and activities within the images. The annotations use color-coded text boxes (pink, blue, green, yellow, orange) to categorize observations and assign likelihoods (e.g., "Likely," "Possibly").
---
### Components/Axes
1. **Main Labels**:
- Top-left: "Concerned look on face"
- Top-right: "Wall of drinks in the back"
- Middle: "Smoke, an outdoor gathering with food"
- Bottom-left: "A single family home across the street"
- Bottom-right: "A lot of architectural decoration and a grand entrance on a beautiful brick building"
2. **Magnifying Glass Captions**:
- Top-left: "Likely something is happening in the store"
- Top-right: "Possibly there is an airplane hangar beyond this station"
- Middle: "Possibly something is being grilled to eat at the party"
- Bottom-left: "Likely this is a residential neighborhood"
- Bottom-right: "Possibly this is a museum"
3. **Text Box Labels and Content**:
- **Pink Boxes** (e.g., "Business suit and coat worn on person"):
- "Likely this person just left work"
- "Likely her skin is sensitive"
- "A woman wearing a wide brim hat"
- **Blue Boxes** (e.g., "Covered wrapped in arms"):
- "Likely there's a baby in the cover"
- "Likely he needs to relax"
- "Smooth asphalt in the driveway"
- **Green Boxes** (e.g., "Smoke, an outdoor gathering with food"):
- "Possibly something is being grilled to eat at the party"
- "A lot of people gathered, tables with food, a colorful sign"
- "A woman is holding hand with a man walking down the pavement"
- **Yellow Boxes** (e.g., "Wall of drinks in the back"):
- "Likely this is a store"
- "Likely this is a lunch party"
- **Orange Boxes** (e.g., "Wet pavement"):
- "Definitely it is raining"
- "Possibly this is a museum"
---
### Detailed Analysis
1. **Top-left Image**:
- A woman in a business suit holds a baby.
- **Observations**:
- Pink box: "Business suit and coat worn on person" → "Likely this person just left work."
- Blue box: "Covered wrapped in arms" → "Likely there's a baby in the cover."
2. **Top-right Image**:
- A train station with a green train and distant wing of an airplane.
- **Observations**:
- Orange box: "Wall of drinks in the back" → "Likely this is a store."
- Green box: "Wing of airplane in distance" → "Possibly there is an airplane hangar beyond this station."
3. **Middle Image**:
- Outdoor gathering with people, tables, and smoke.
- **Observations**:
- Green box: "Smoke, an outdoor gathering with food" → "Possibly something is being grilled to eat at the party."
- Pink box: "A woman wearing a wide brim hat" → "Likely her skin is sensitive."
- Blue box: "A man smoking a cigarette" → "Likely he needs to relax."
4. **Bottom-left Image**:
- A child near a hedge and asphalt driveway.
- **Observations**:
- Pink box: "A big hedgerow next to asphalt" → No explicit inference.
- Green box: "A single family home across the street" → "Likely this is a residential neighborhood."
- Orange box: "Wet pavement" → "Definitely it is raining."
5. **Bottom-right Image**:
- A grand brick building with parked cars and pedestrians.
- **Observations**:
- Orange box: "A lot of architectural decoration and a grand entrance on a beautiful brick building" → "Possibly this is a museum."
- Green box: "A woman is holding hand with a man walking down the pavement" → "Likely they are husband and wife."
- Blue box: "Some cars parked on the side of the street with tall buildings around it" → No explicit inference.
---
### Key Observations
- **Likelihood Indicators**:
- "Likely" (pink/blue boxes) suggests high confidence in observations (e.g., "Likely this person just left work").
- "Possibly" (green/orange boxes) indicates speculative inferences (e.g., "Possibly this is a museum").
- **Recurring Themes**:
- Human activity (e.g., "Likely he needs to relax," "Likely they are husband and wife").
- Environmental context (e.g., "Wet pavement," "Smooth asphalt").
- **Color Coding**:
- Pink/blue boxes focus on human subjects and immediate actions.
- Green/yellow/orange boxes emphasize environmental or contextual details.
---
### Interpretation
The annotations function as a hybrid of observational notes and speculative reasoning, using color and likelihood labels to structure interpretations. For example:
- The use of "Likely" in pink/blue boxes ties human behavior (e.g., wearing a business suit, holding a baby) to plausible conclusions (e.g., "just left work," "there's a baby in the cover").
- "Possibly" in green/orange boxes highlights uncertain but contextually plausible inferences (e.g., "airplane hangar," "museum").
- Environmental cues (e.g., "wet pavement," "smooth asphalt") ground observations in physical reality, while architectural details (e.g., "grand entrance") suggest institutional or public spaces.
The annotations collectively demonstrate how visual cues (e.g., clothing, weather, architecture) are used to infer narratives about people, places, and activities. The absence of explicit legends implies a standardized color-coding system for categorizing observations (e.g., pink for human subjects, green for environmental context).
DECODING INTELLIGENCE...