\n
## Image Analysis: Scene Annotations
### Overview
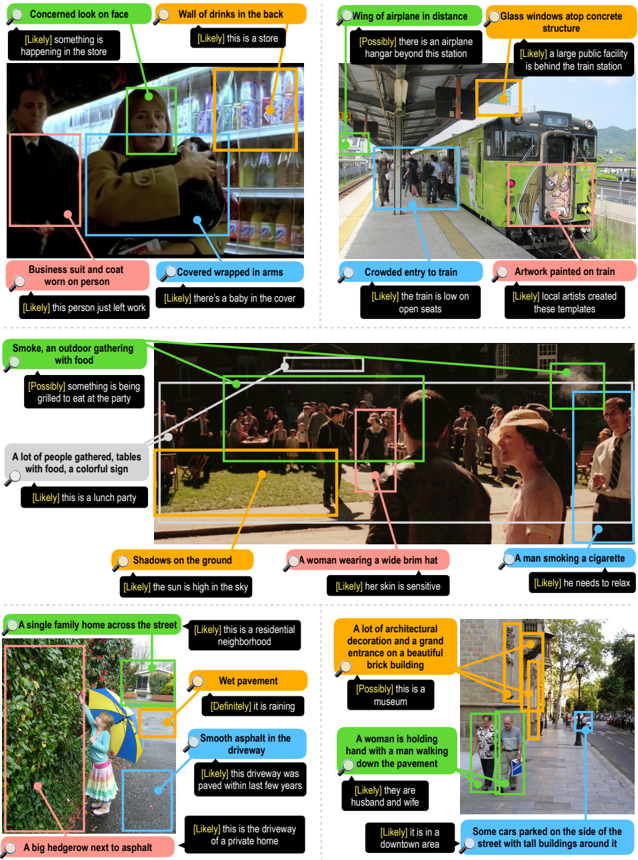
The image presents a collection of annotated scenes, appearing to be stills from a video or a series of photographs. Each scene is enclosed in a yellow bounding box with a textual description above it, including a confidence level indicated by bracketed phrases like "[Likely]" or "[Definitely]". The annotations describe various elements within each scene, suggesting an attempt to interpret the context and activities occurring.
### Components/Axes
There are no axes or traditional chart components. The image is organized as a grid of scenes, each with its own annotation. The annotations themselves consist of a descriptive phrase and a confidence level.
### Detailed Analysis or Content Details
Here's a transcription of each annotation, along with its associated scene:
1. **Concerned look on face:** "[Likely] something is happening in the store."
2. **Wall of drinks in the back:** "[Likely] this is a store."
3. **Wing of airplane in distance:** "[Possibly] there is an airplane hangar beyond this station."
4. **Glass windows atop concrete structure:** "[Likely] a large public facility is behind the train station."
5. **Business suit and coat worn on person:** "[Likely] this person just left work."
6. **Covered wrapped in arms:** "[Likely] there's a baby in the cover."
7. **Crowded entry to train:** "[Likely] the train is low on open seats."
8. **Artwork painted on train:** "[Likely] local artists created these templates."
9. **Smoke, an outdoor gathering with food:** "[Possibly] something is being grilled to eat at the party."
10. **A lot of people gathered, tables with food, a colorful quilt:** "[Likely] this is a lunch party."
11. **Shadows on the ground:** "[Likely] the sun is high in the sky."
12. **A woman wearing a wide brim hat:** "[Likely] her skin is sensitive."
13. **A man smoking a cigarette:** "[Likely] he needs to relax."
14. **A single family home across the street:** "[Likely] this is a residential neighborhood."
15. **Wet pavement:** "[Definitely] it is raining."
16. **A lot of architectural decoration and a grand entrance on a beautiful brick building:** "[Possibly] this is a museum."
17. **Smooth asphalt in the driveway:** "[Likely] this driveway was paved within last few years."
18. **A woman is holding hand with a man walking down the pavement:** "[Likely] they are husband and wife."
19. **A big hedgerow next to asphalt:** "[Likely] this is the driveway of a private home."
20. **Some cars parked on the side of the street with tall buildings around it:** "[Likely] it is in a downtown area."
### Key Observations
* The annotations are subjective interpretations of the scenes, with varying degrees of confidence.
* The annotations frequently use the word "[Likely]", indicating a degree of uncertainty.
* The scenes depict a variety of everyday situations, including shopping, commuting, social gatherings, and residential areas.
* The annotations suggest an attempt to infer activities or characteristics based on visual cues.
* The annotations are not quantitative; they are purely descriptive.
### Interpretation
The image appears to be part of a dataset used for training a computer vision model to understand and interpret scenes. The annotations provide ground truth labels for the model, allowing it to learn to associate visual features with contextual information. The varying confidence levels suggest that some scenes are more easily interpreted than others. The annotations demonstrate the challenges of scene understanding, as even seemingly simple scenes can be open to multiple interpretations. The annotations are not based on facts or data, but rather on interpretations of the scenes. The image is a demonstration of the need for human-level reasoning in computer vision. The annotations are a form of qualitative data, providing insights into the subjective nature of scene understanding. The annotations are a form of "common sense" knowledge, which is difficult to encode into a computer program. The annotations are a form of "situated cognition," meaning that the interpretation of a scene depends on the context in which it is viewed. The annotations are a form of "grounded cognition," meaning that the interpretation of a scene is based on sensory experience.