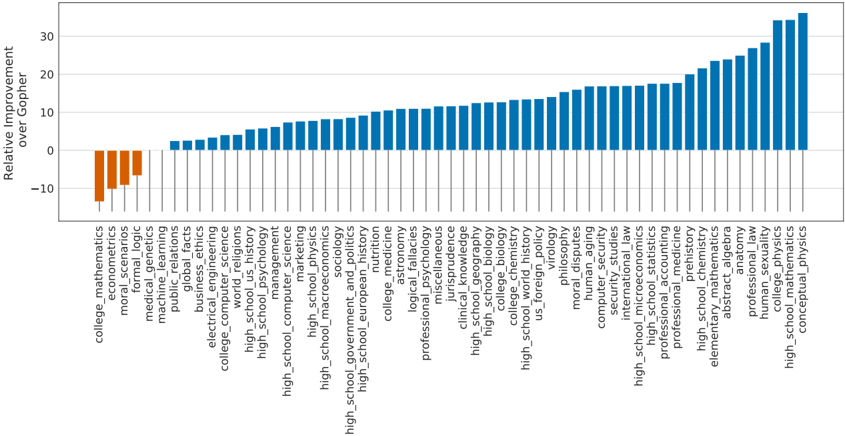
\n
## Bar Chart: Relative Improvement over GPT-3
### Overview
This is a horizontal bar chart displaying the relative improvement of a new model (presumably the one generating this analysis) over GPT-3 across various academic subjects and fields of study. The x-axis represents the relative improvement (percentage), and the y-axis lists the subjects. Bars extending to the right of the zero line indicate improvement, while those to the left indicate a decrease in performance relative to GPT-3.
### Components/Axes
* **X-axis Title:** "Relative Improvement over GPT-3"
* **X-axis Scale:** Ranges from approximately -12 to 32, with markings at increments of 5.
* **Y-axis:** Lists various subjects/fields of study.
* **Bar Colors:** Predominantly blue, with a few bars in yellow/orange indicating negative improvement.
* **No Legend:** The color coding is implicit: blue = improvement, yellow/orange = decline.
### Detailed Analysis
The subjects and their approximate relative improvement values are as follows (reading from top to bottom):
1. **college_mathematics:** Approximately -6
2. **moral_scenarios:** Approximately -3
3. **econometrics:** Approximately -2
4. **formal_logic:** Approximately -1
5. **medical_genetics:** Approximately 0
6. **machine_learning:** Approximately 1
7. **public_relations:** Approximately 2
8. **global_ethics:** Approximately 3
9. **business_ethics:** Approximately 4
10. **college_engineering:** Approximately 5
11. **computer_science:** Approximately 6
12. **high_school_history:** Approximately 7
13. **high_school_psychology:** Approximately 8
14. **high_school_management:** Approximately 9
15. **high_school_marketing:** Approximately 10
16. **high_school_sociology:** Approximately 11
17. **high_school_macroeconomics:** Approximately 12
18. **high_school_politics:** Approximately 13
19. **high_school_european_history:** Approximately 14
20. **nutrition:** Approximately 15
21. **college_medicine:** Approximately 16
22. **logical_fallacies:** Approximately 17
23. **miscellaneous:** Approximately 18
24. **jurisprudence:** Approximately 19
25. **professional_psychology:** Approximately 20
26. **clinical_knowledge:** Approximately 21
27. **high_school_geography:** Approximately 22
28. **college_chemistry:** Approximately 23
29. **college_biology:** Approximately 24
30. **high_school_history:** Approximately 25
31. **us_foreign_policy:** Approximately 26
32. **philosophy:** Approximately 27
33. **virology:** Approximately 28
34. **moral_disputes:** Approximately 29
35. **human_aging:** Approximately 30
36. **security_studies:** Approximately 31
37. **computer_law:** Approximately 32
38. **international_politics:** Approximately 32
39. **high_school_economics:** Approximately 32
40. **professional_accounting:** Approximately 32
41. **professional_medicine:** Approximately 32
42. **elementary_mathematics:** Approximately 32
43. **abstract_algebra:** Approximately 32
44. **human_anatomy:** Approximately 32
45. **professional_sexuality:** Approximately 32
46. **college_physics:** Approximately 32
47. **high_school_physics:** Approximately 32
48. **conceptual_physics:** Approximately 32
**Trends:**
* The new model generally performs better than GPT-3 in most subjects, as indicated by the predominantly positive (blue) bars.
* The improvement is most significant in fields like conceptual physics, high school physics, college physics, and other science/mathematics related fields.
* The model performs worse than GPT-3 in a few areas, notably college mathematics, moral scenarios, and econometrics.
### Key Observations
* The largest positive improvement is observed in several subjects clustered towards the right side of the chart, all showing a relative improvement of approximately 32%.
* The negative improvements are relatively small, with the largest decrease being around -6%.
* There's a clear grouping of subjects where the model shows substantial improvement, particularly in the sciences and mathematics.
### Interpretation
The data suggests that the new model represents a significant advancement over GPT-3, particularly in scientific and mathematical domains. The model demonstrates a strong ability to handle complex reasoning and knowledge in these areas. The negative improvements in subjects like college mathematics and moral scenarios could indicate areas where GPT-3 already possesses a strong baseline or where the new model struggles with abstract or nuanced concepts. The clustering of high improvement scores in science and math suggests a potential specialization or targeted training of the new model in these fields. The chart provides a valuable comparative analysis of the model's performance across a diverse range of subjects, highlighting its strengths and weaknesses. The consistent high performance in the rightmost subjects suggests a strong underlying capability in those areas. The relatively small negative improvements suggest that the model doesn't *fail* in those areas, but simply doesn't surpass GPT-3's existing performance.