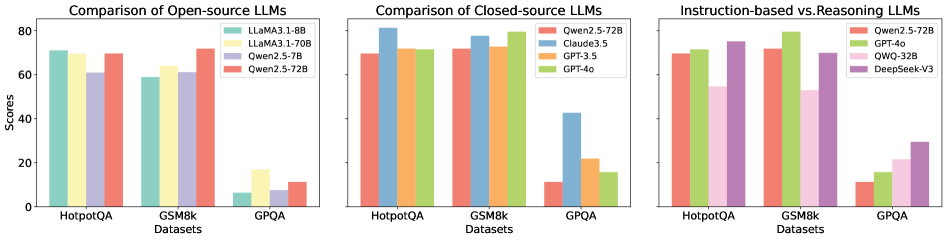
## Bar Charts: LLM Performance Comparison
### Overview
The image presents three bar charts comparing the performance of various Large Language Models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. The first chart focuses on open-source LLMs, the second on closed-source LLMs, and the third on instruction-based vs. reasoning LLMs. The y-axis represents "Scores," while the x-axis represents the datasets.
### Components/Axes
* **Y-axis:** "Scores" (Scale from 0 to 80, increments of 10)
* **X-axis:** "Datasets" (Categories: HotpotQA, GSM8k, GPQA)
* **Chart 1 (Open-source LLMs):**
* Legend:
* LLaMA1-8B (Light Blue)
* LLaMA2.1-70B (Yellow)
* Owen2.5-7B (Light Orange)
* Owen2.5-728 (Red)
* **Chart 2 (Closed-source LLMs):**
* Legend:
* Qwen2.5-72B (Light Green)
* Claude3.5 (Purple)
* GPT-3.5 (Dark Green)
* GPT-4o (Blue)
* **Chart 3 (Instruction-based vs. Reasoning LLMs):**
* Legend:
* Qwen2.5-72B (Light Green)
* GPT-4o (Blue)
* QWQ-32B (Dark Yellow)
* DeepSeek-V3 (Light Purple)
### Detailed Analysis or Content Details
**Chart 1: Comparison of Open-source LLMs**
* **HotpotQA:**
* LLaMA1-8B: Approximately 74
* LLaMA2.1-70B: Approximately 77
* Owen2.5-7B: Approximately 62
* Owen2.5-728: Approximately 65
* **GSM8k:**
* LLaMA1-8B: Approximately 60
* LLaMA2.1-70B: Approximately 65
* Owen2.5-7B: Approximately 60
* Owen2.5-728: Approximately 63
* **GPQA:**
* LLaMA1-8B: Approximately 10
* LLaMA2.1-70B: Approximately 12
* Owen2.5-7B: Approximately 8
* Owen2.5-728: Approximately 10
**Chart 2: Comparison of Closed-source LLMs**
* **HotpotQA:**
* Qwen2.5-72B: Approximately 79
* Claude3.5: Approximately 74
* GPT-3.5: Approximately 70
* GPT-4o: Approximately 76
* **GSM8k:**
* Qwen2.5-72B: Approximately 72
* Claude3.5: Approximately 68
* GPT-3.5: Approximately 65
* GPT-4o: Approximately 70
* **GPQA:**
* Qwen2.5-72B: Approximately 30
* Claude3.5: Approximately 25
* GPT-3.5: Approximately 15
* GPT-4o: Approximately 32
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **HotpotQA:**
* Qwen2.5-72B: Approximately 74
* GPT-4o: Approximately 76
* QWQ-32B: Approximately 70
* DeepSeek-V3: Approximately 72
* **GSM8k:**
* Qwen2.5-72B: Approximately 68
* GPT-4o: Approximately 72
* QWQ-32B: Approximately 65
* DeepSeek-V3: Approximately 67
* **GPQA:**
* Qwen2.5-72B: Approximately 10
* GPT-4o: Approximately 12
* QWQ-32B: Approximately 8
* DeepSeek-V3: Approximately 9
### Key Observations
* Across all datasets, LLaMA2.1-70B consistently outperforms LLaMA1-8B.
* Qwen2.5-72B generally achieves the highest scores among the closed-source models, particularly on HotpotQA and GSM8k.
* GPT-4o consistently performs well across all datasets, often rivaling or exceeding Qwen2.5-72B.
* GPQA consistently yields the lowest scores for all models, indicating it is the most challenging dataset.
* The performance differences between models are more pronounced on HotpotQA and GSM8k than on GPQA.
### Interpretation
The data suggests that larger models (e.g., LLaMA2.1-70B vs. LLaMA1-8B) generally perform better. Closed-source models, particularly Qwen2.5-72B and GPT-4o, tend to outperform open-source models. The varying performance across datasets indicates that the difficulty of the task significantly impacts model performance. GPQA, being the most challenging dataset, reveals the limitations of current LLMs in complex reasoning tasks. The comparison of instruction-based vs. reasoning LLMs (Chart 3) shows that GPT-4o and Qwen2.5-72B are strong performers in both categories, while QWQ-32B and DeepSeek-V3 show slightly lower, but still competitive, results. This suggests that both instruction-following and reasoning capabilities are crucial for achieving high scores on these benchmarks. The consistent trends across the three charts provide a robust basis for comparing the relative strengths and weaknesses of different LLMs.