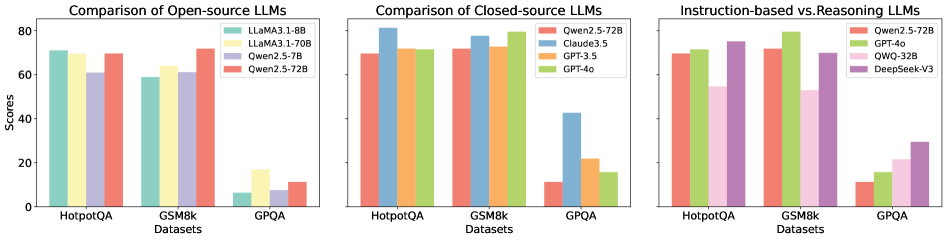
## Bar Chart: Comparison of LLMs Across Datasets
### Overview
The image presents three grouped bar charts comparing the performance of various large language models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. The charts are divided into:
1. **Open-source LLMs** (LLaMA, Qwen)
2. **Closed-source LLMs** (Qwen, Claude, GPT)
3. **Instruction-based vs. Reasoning LLMs** (Qwen, GPT, QWQ, DeepSeek)
### Components/Axes
- **X-axis**: Datasets (HotpotQA, GSM8k, GPQA)
- **Y-axis**: Scores (0–80)
- **Legends**:
- **Open-source**: LLaMA 3.1-8B (green), LLaMA 3.1-70B (yellow), Qwen 2.5-7B (purple), Qwen 2.5-72B (red)
- **Closed-source**: Qwen 2.5-72B (red), Claude 3.5 (blue), GPT-3.5 (orange), GPT-4o (green)
- **Instruction vs. Reasoning**: Qwen 2.5-72B (red), GPT-4o (green), QWQ-32B (pink), DeepSeek-V3 (purple)
### Detailed Analysis
#### Open-source LLMs
- **HotpotQA**:
- LLaMA 3.1-8B: ~70
- LLaMA 3.1-70B: ~68
- Qwen 2.5-7B: ~60
- Qwen 2.5-72B: ~70
- **GSM8k**:
- LLaMA 3.1-8B: ~60
- LLaMA 3.1-70B: ~65
- Qwen 2.5-7B: ~60
- Qwen 2.5-72B: ~70
- **GPQA**:
- LLaMA 3.1-8B: ~5
- LLaMA 3.1-70B: ~15
- Qwen 2.5-7B: ~5
- Qwen 2.5-72B: ~10
#### Closed-source LLMs
- **HotpotQA**:
- Qwen 2.5-72B: ~70
- Claude 3.5: ~80
- GPT-3.5: ~70
- GPT-4o: ~70
- **GSM8k**:
- Qwen 2.5-72B: ~70
- Claude 3.5: ~75
- GPT-3.5: ~70
- GPT-4o: ~80
- **GPQA**:
- Qwen 2.5-72B: ~10
- Claude 3.5: ~40
- GPT-3.5: ~20
- GPT-4o: ~15
#### Instruction-based vs. Reasoning LLMs
- **HotpotQA**:
- Qwen 2.5-72B: ~70
- GPT-4o: ~70
- QWQ-32B: ~50
- DeepSeek-V3: ~70
- **GSM8k**:
- Qwen 2.5-72B: ~70
- GPT-4o: ~80
- QWQ-32B: ~50
- DeepSeek-V3: ~70
- **GPQA**:
- Qwen 2.5-72B: ~10
- GPT-4o: ~15
- QWQ-32B: ~20
- DeepSeek-V3: ~30
### Key Observations
1. **Open-source models** (LLaMA, Qwen) show strong performance on HotpotQA and GSM8k but struggle significantly on GPQA (scores <20 for all models).
2. **Closed-source models** (Claude 3.5, GPT-4o) consistently outperform open-source models, especially on GPQA (e.g., Claude 3.5 scores ~40 vs. LLaMA 3.1-70B’s ~15).
3. **Instruction-based models** (QWQ-32B) underperform across all datasets compared to reasoning-focused models like DeepSeek-V3, which achieves ~30 on GPQA (vs. QWQ-32B’s ~20).
### Interpretation
- **Model Size vs. Performance**: Larger open-source models (e.g., LLaMA 3.1-70B) outperform smaller variants (8B) but still lag behind closed-source models.
- **Closed-source Advantage**: Proprietary models (Claude 3.5, GPT-4o) demonstrate superior reasoning capabilities, particularly on GPQA, suggesting optimized architectures or training data.
- **Instruction vs. Reasoning**: Models like DeepSeek-V3 (reasoning-focused) outperform instruction-based models (QWQ-32B) on GPQA, highlighting the importance of reasoning capabilities for complex tasks.
- **GPQA as a Bottleneck**: All models score poorly on GPQA, indicating it is a highly challenging dataset requiring advanced reasoning skills.
### Spatial Grounding & Trend Verification
- **Legend Placement**:
- Open-source: Top-left of first chart
- Closed-source: Top-right of second chart
- Instruction vs. Reasoning: Top-left of third chart
- **Color Consistency**: All colors in legends match bar colors across charts (e.g., red = Qwen 2.5-72B in all contexts).
- **Trend Validation**:
- Open-source models show a downward trend on GPQA (e.g., LLaMA 3.1-70B drops from ~68 to ~15).
- Closed-source models maintain higher scores across datasets (e.g., GPT-4o scores ~70–80).
### Critical Insights
- **Open-source Limitations**: While competitive on general tasks (HotpotQA/GSM8k), open-source models lack the reasoning depth for specialized benchmarks like GPQA.
- **Closed-source Dominance**: Proprietary models achieve near-human-like performance on reasoning tasks, underscoring the gap between open and closed ecosystems.
- **Instruction vs. Reasoning Tradeoff**: Instruction-based models excel at following directions but struggle with abstract reasoning, whereas models like DeepSeek-V3 balance both.