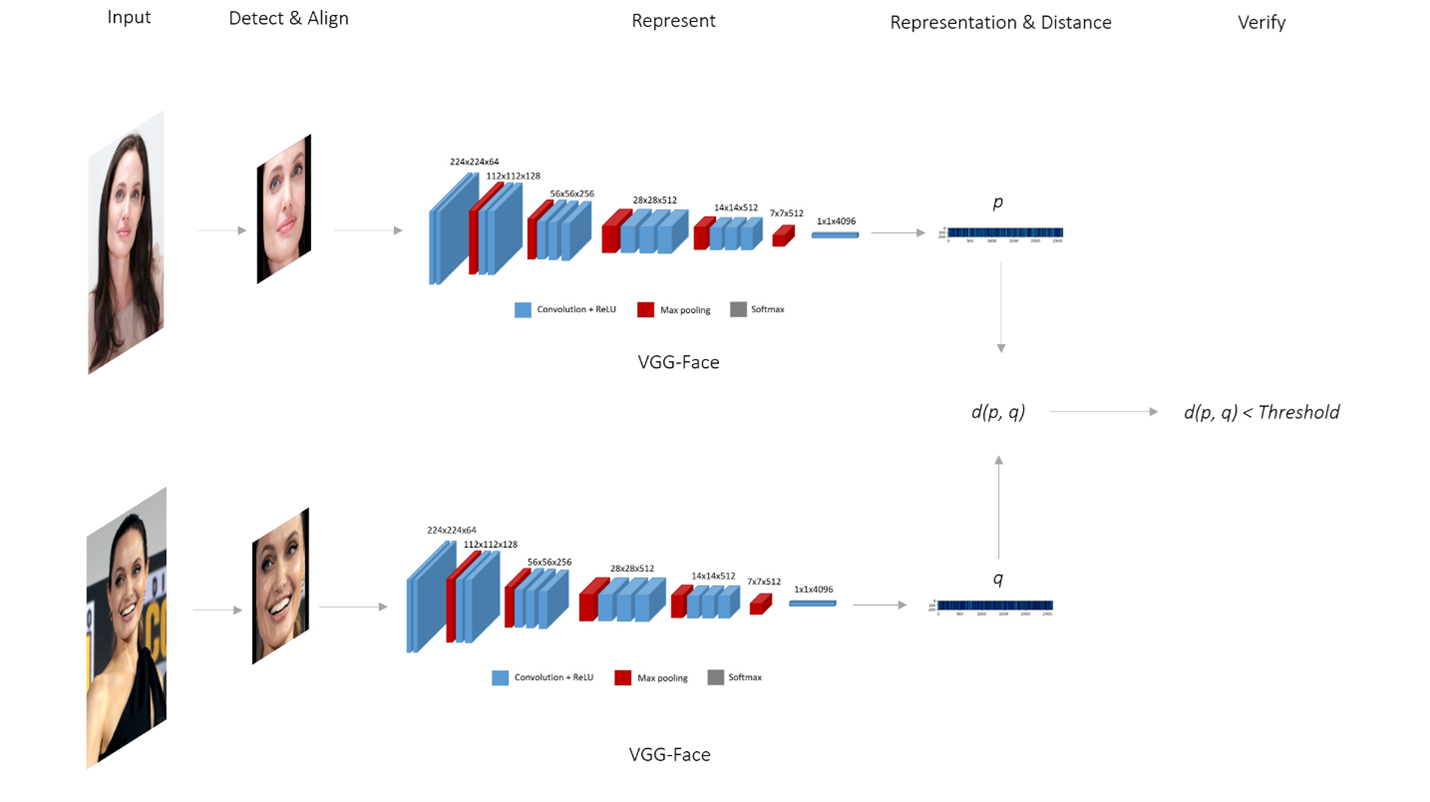
## Diagram: VGG-Face Network Architecture for Face Verification
### Overview
The image illustrates the architecture of a VGG-Face convolutional neural network used for face verification. It shows the flow of data from input images through the network to a final verification step, comparing the representations of two faces.
### Components/Axes
* **Top Labels (Left to Right):** Input, Detect & Align, Represent, Representation & Distance, Verify
* **Network Layers:** The network consists of multiple convolutional layers (blue), max pooling layers (red), and softmax layers (gray).
* **Layer Dimensions:** The dimensions of each layer are indicated above the corresponding block (e.g., 224x224x64, 112x112x128, 56x56x256, 28x28x512, 14x14x512, 7x7x512, 1x1x4096).
* **Legend (Bottom-Center):**
* Blue: Convolution + ReLU
* Red: Max pooling
* Gray: Softmax
* **VGG-Face Labels:** Located below the network representation for both the top and bottom paths.
* **Distance Comparison:** The representations 'p' and 'q' are compared using a distance function d(p, q), which is then compared to a threshold.
### Detailed Analysis
The diagram shows two parallel paths, each processing a different face image.
**Top Path:**
1. **Input:** A photograph of a woman.
2. **Detect & Align:** The face is detected and aligned.
3. **Represent:** The aligned face is fed into the VGG-Face network.
* The network consists of the following layers:
* A stack of blue "Convolution + ReLU" layers, starting with dimensions 224x224x64, followed by 112x112x128, 56x56x256, 28x28x512, 14x14x512, 7x7x512, and finally 1x1x4096.
* Red "Max pooling" layers interspersed between the convolutional layers.
* A gray "Softmax" layer at the end.
4. **Representation & Distance:** The output of the network is a representation 'p'.
**Bottom Path:**
1. **Input:** A photograph of a woman.
2. **Detect & Align:** The face is detected and aligned.
3. **Represent:** The aligned face is fed into the VGG-Face network.
* The network consists of the following layers:
* A stack of blue "Convolution + ReLU" layers, starting with dimensions 224x224x64, followed by 112x112x128, 56x56x256, 28x28x512, 14x14x512, 7x7x512, and finally 1x1x4096.
* Red "Max pooling" layers interspersed between the convolutional layers.
* A gray "Softmax" layer at the end.
4. **Representation & Distance:** The output of the network is a representation 'q'.
**Verification:**
* The representations 'p' and 'q' are compared using a distance function d(p, q).
* The result of the distance function is compared to a threshold: d(p, q) < Threshold.
### Key Observations
* The VGG-Face network is used to extract feature representations from face images.
* The architecture consists of convolutional, max pooling, and softmax layers.
* The dimensions of the layers decrease as the data flows through the network, indicating feature extraction and dimensionality reduction.
* The final verification step compares the distance between the representations of two faces to a threshold.
### Interpretation
The diagram illustrates a common approach to face verification using deep learning. The VGG-Face network learns to extract discriminative features from face images, allowing for comparison and verification. The distance function d(p, q) measures the similarity between the feature representations of two faces. If the distance is below a certain threshold, the faces are considered to belong to the same person. This architecture is used in various applications, such as facial recognition, identity verification, and access control.