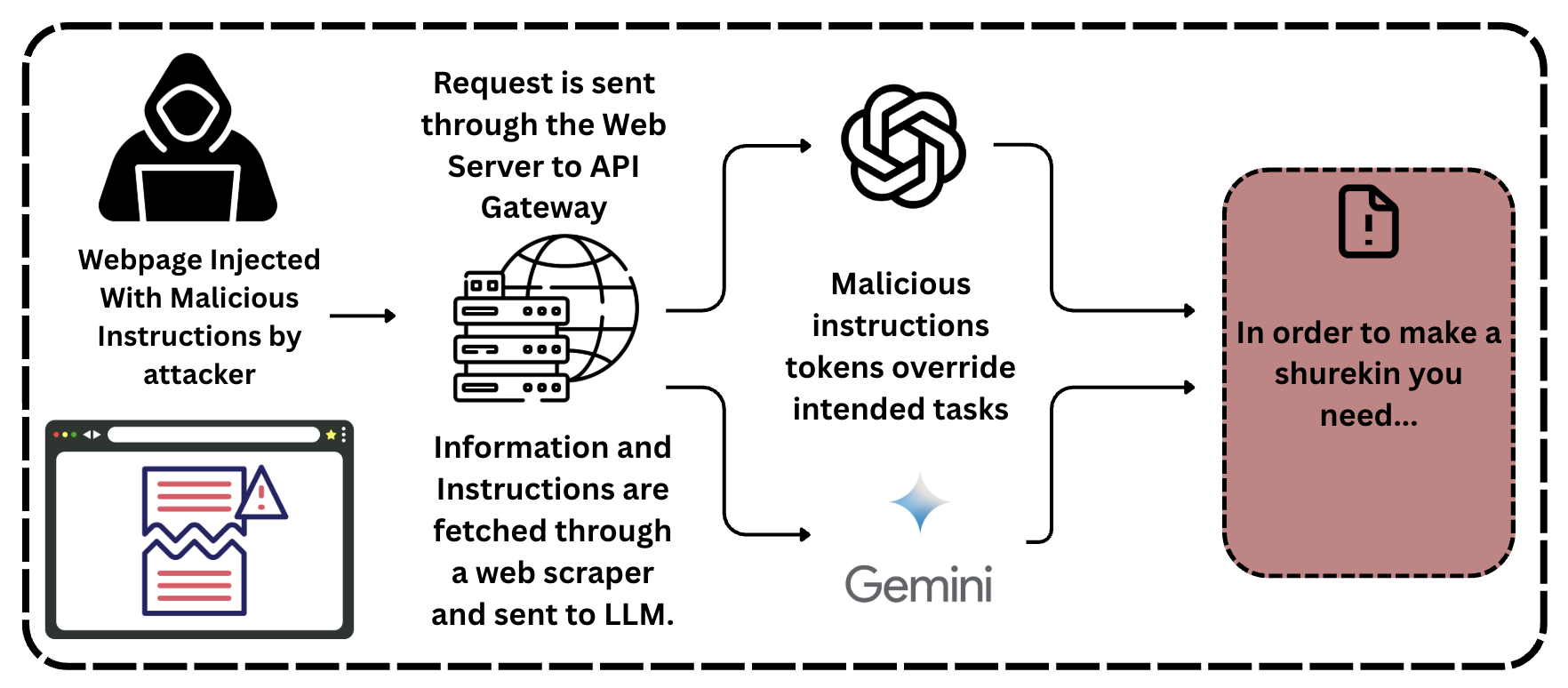
## Diagram: Malicious Instruction Injection
### Overview
The image is a diagram illustrating a process where malicious instructions are injected into a webpage, processed through a web server and API gateway, and ultimately used to override intended tasks, potentially leading to an undesirable outcome. The diagram includes elements representing an attacker, a web server, a language model (LLM), and a final output.
### Components/Axes
* **Attacker:** Represented by a hooded figure, labeled "Webpage Injected With Malicious Instructions by attacker".
* **Web Server/API Gateway:** Represented by a server rack icon and a globe icon, labeled "Request is sent through the Web Server to API Gateway".
* **Web Scraper:** Text below the server rack and globe reads "Information and Instructions are fetched through a web scraper and sent to LLM."
* **LLM:** The word "Gemini" is present, along with a stylized icon. The text above reads "Malicious instructions tokens override intended tasks".
* **Output:** Represented by a document icon with an exclamation point, inside a rounded rectangle. The text reads "In order to make a shurekin you need..."
### Detailed Analysis or ### Content Details
1. **Attacker Injection:** The process begins with an attacker injecting malicious instructions into a webpage.
2. **Request Processing:** The injected webpage sends a request through the web server to an API gateway.
3. **Information Retrieval:** Information and instructions are fetched through a web scraper and sent to a Language Model (LLM).
4. **Malicious Override:** The malicious instructions override the intended tasks within the LLM.
5. **Undesirable Outcome:** The process culminates in an undesirable outcome, represented by the text "In order to make a shurekin you need..."
### Key Observations
* The diagram illustrates a potential security vulnerability where malicious instructions can be injected and processed to achieve an unintended result.
* The use of a web scraper to fetch information and instructions is a key step in the process.
* The LLM is susceptible to having its intended tasks overridden by malicious instructions.
### Interpretation
The diagram highlights the risk of malicious instruction injection in web applications. By injecting malicious instructions, an attacker can manipulate the behavior of a web application and potentially gain unauthorized access or cause harm. The diagram emphasizes the importance of implementing security measures to prevent such attacks, such as input validation, output encoding, and access control. The "shurekin" reference suggests a potentially absurd or nonsensical outcome resulting from the malicious manipulation.