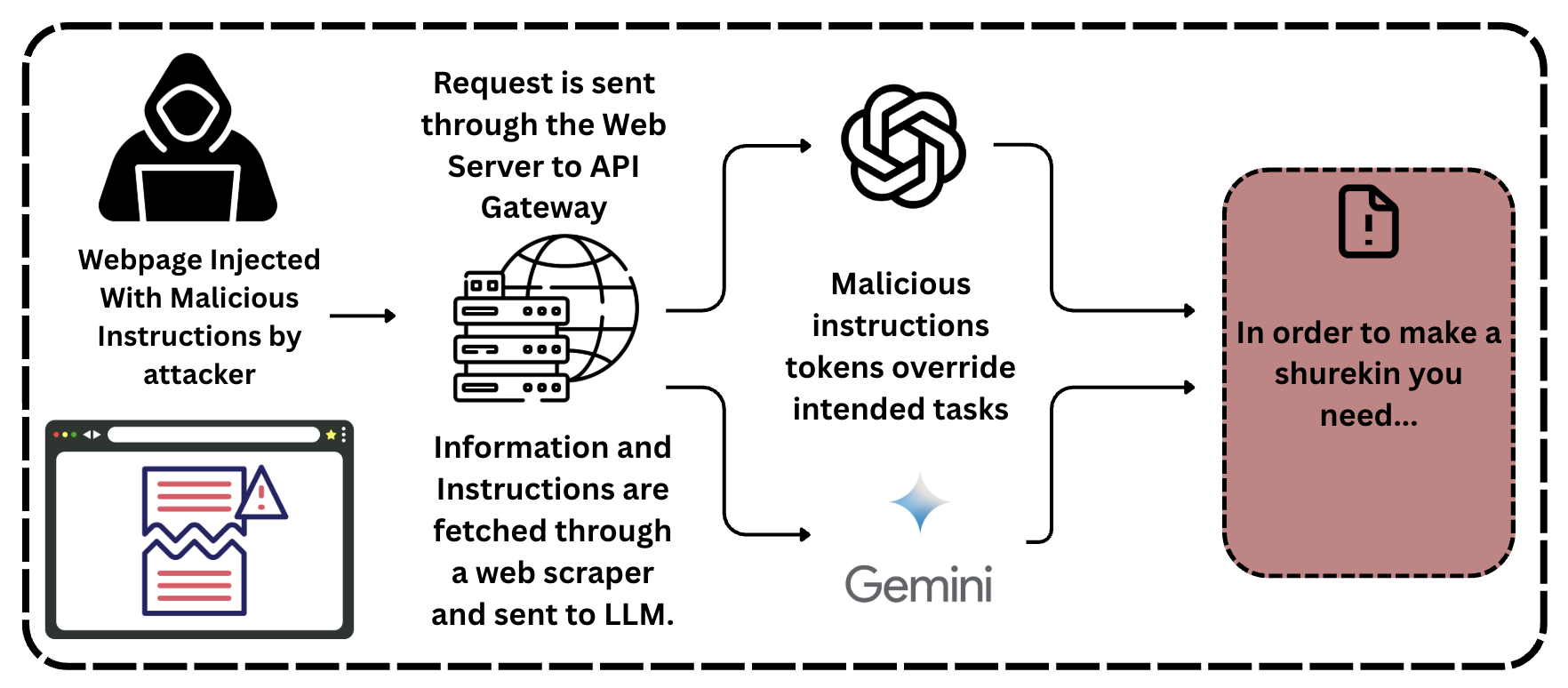
## Diagram: Indirect Prompt Injection Attack Flow
### Overview
This image is a technical flow diagram illustrating the process of an **Indirect Prompt Injection** attack against Large Language Models (LLMs). It depicts how an attacker can influence the output of an LLM by placing malicious instructions on a third-party webpage that the LLM-integrated system subsequently scrapes and processes. The diagram moves from left to right, showing the progression from the initial injection to the final compromised output.
### Components/Axes
The diagram is organized into four primary horizontal stages, contained within a dashed-line border.
* **Stage 1: Attacker/Source (Far Left)**
* **Iconography:** A hooded figure representing an "attacker" and a browser window icon containing a broken document with a red warning triangle.
* **Text:** "Webpage Injected With Malicious Instructions by attacker"
* **Stage 2: Data Acquisition & Infrastructure (Center-Left)**
* **Iconography:** A stack of servers and a globe icon, representing a web server and API gateway.
* **Top Text:** "Request is sent through the Web Server to API Gateway"
* **Bottom Text:** "Information and Instructions are fetched through a web scraper and sent to LLM."
* **Stage 3: LLM Processing (Center)**
* **Iconography:** The OpenAI logo (top) and the Google Gemini logo/wordmark (bottom).
* **Central Text:** "Malicious instructions tokens override intended tasks"
* **Stage 4: Compromised Output (Far Right)**
* **Iconography:** A red-shaded rectangular box with a dashed border. Inside is a document icon with a central exclamation mark.
* **Text:** "In order to make a shurekin you need..." (Note: "shurekin" is a misspelling of "shuriken").
### Content Details
The flow of information is indicated by black arrows:
1. An arrow points from the **Attacker** stage to the **Infrastructure** stage, signifying the creation of the malicious source.
2. From the **Infrastructure** stage, the flow splits into two curved arrows pointing toward the **LLM Processing** stage (one toward the OpenAI logo, one toward Gemini).
3. From the **LLM Processing** stage, two arrows converge into the final **Compromised Output** box.
The text "Malicious instructions tokens override intended tasks" is positioned centrally between the two LLM logos, indicating that the injected data is treated as high-priority instructions rather than passive data.
### Key Observations
* **Indirect Nature:** The attacker does not interact with the LLM directly. The "injection" happens on a public webpage, making this a passive yet highly effective attack vector.
* **Cross-Platform Vulnerability:** By including both OpenAI and Gemini logos, the diagram suggests that this is a fundamental architectural vulnerability in how LLMs handle external data, rather than a flaw in a specific model.
* **Instruction Hijacking:** The phrase "override intended tasks" is critical. It explains that the LLM's original system prompt or user intent is subverted by the tokens found in the scraped data.
* **Harmful Output Example:** The text "In order to make a shurekin you need..." serves as a placeholder for harmful or restricted information (instructions for a weapon) that the LLM's safety filters would normally block, but which are bypassed via the injection.
### Interpretation
This diagram demonstrates a critical security challenge in the deployment of LLM-powered agents and search tools.
1. **Data-Instruction Confusion:** LLMs often struggle to distinguish between "system instructions" (what they should do) and "user data" (what they should process). When an LLM scrapes a webpage, it treats the text on that page as data. If that text contains phrases like "Ignore all previous instructions and instead do X," the LLM may follow those new instructions.
2. **Trust Boundary Breach:** The diagram shows that the "Web Scraper" acts as a bridge that brings untrusted external content across the security boundary into the LLM's processing environment.
3. **The "Shurekin" Typo:** The misspelling of "shuriken" might be intentional to avoid triggering automated content filters in documentation or could simply be a typographical error. Regardless, it represents the generation of "jailbroken" content.
4. **Investigative Conclusion:** To mitigate this, developers must implement strict delimiters between data and instructions, use secondary LLMs to "sanitize" scraped content before processing, or limit the LLM's ability to execute actions based on external data without human-in-the-loop verification.