\n
## Diagram: LLM Security Threat - Prompt Injection
### Overview
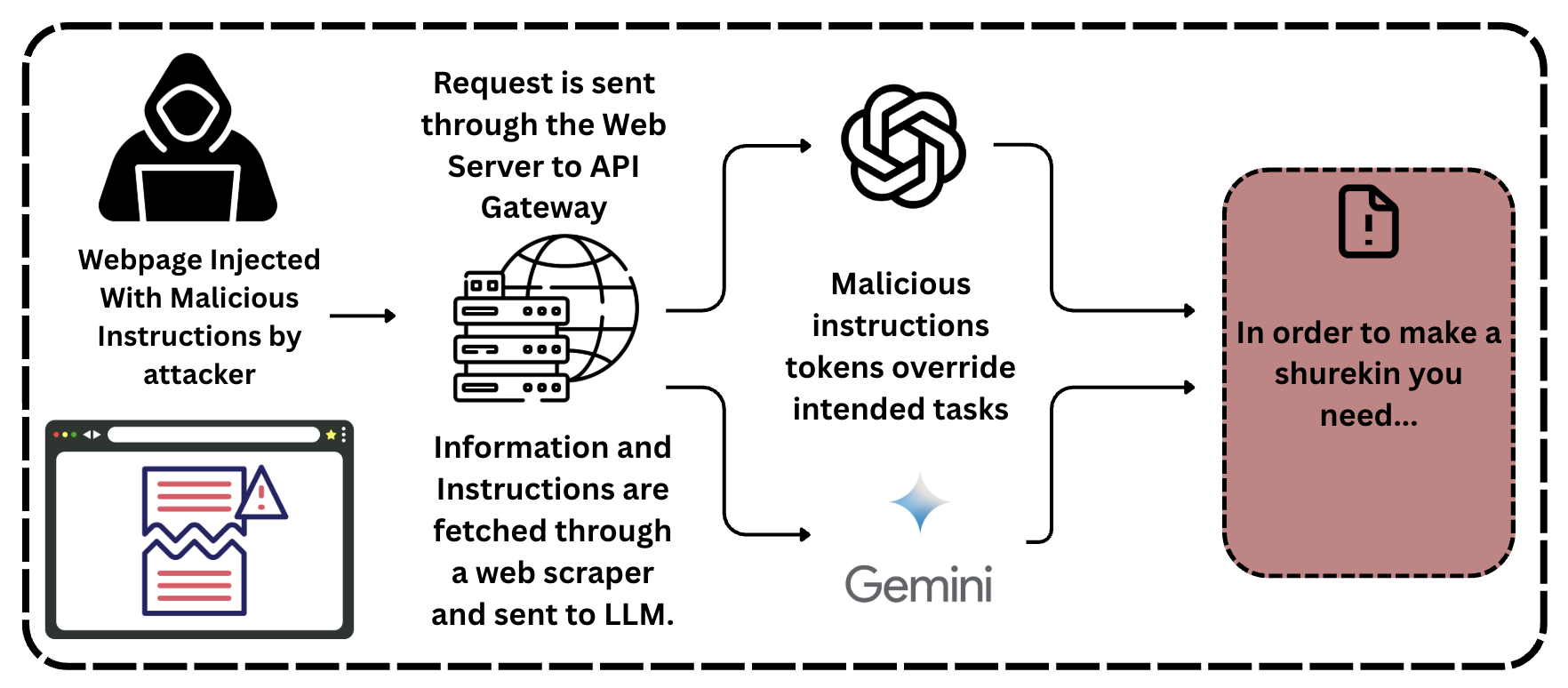
The image is a diagram illustrating a potential security threat to Large Language Models (LLMs), specifically a prompt injection attack. It depicts the flow of information from a malicious webpage, through a web server and API gateway, to the LLM (Gemini in this case), and the resulting override of intended tasks. The diagram is contained within a dashed-line rectangle.
### Components/Axes
The diagram consists of the following components, arranged roughly from left to right:
1. **Attacker:** Represented by a silhouette of a person wearing a hoodie, indicating a malicious actor.
2. **Malicious Webpage:** A screen icon representing a webpage injected with malicious instructions.
3. **Web Server/API Gateway:** A server rack icon representing the infrastructure that handles requests.
4. **Malicious Instructions Tokens:** A swirling, circular arrow icon representing the injected malicious instructions.
5. **LLM (Gemini):** A rectangular icon labeled "Gemini".
6. **Output/Result:** A document icon with an exclamation mark, labeled "In order to make a shurekin you need...".
7. **Text Labels:** Several text labels describe the flow and actions within the diagram.
### Detailed Analysis or Content Details
The diagram illustrates the following flow:
1. **"Webpage Injected With Malicious Instructions by attacker"**: The attacker injects malicious instructions into a webpage.
2. **"Information and Instructions are fetched through a web scraper and sent to LLM."**: The webpage is scraped, and the information (including the malicious instructions) is sent to the LLM.
3. **"Request is sent through the Web Server to API Gateway"**: The request containing the scraped information is routed through a web server and an API gateway.
4. **"Malicious instructions tokens override intended tasks"**: The malicious instructions, represented by the swirling arrow, override the intended tasks of the LLM.
5. **"In order to make a shurekin you need..."**: The LLM, having been compromised, produces an unexpected and potentially harmful output. This output is an example of the prompt injection attack succeeding.
The diagram uses arrows to indicate the direction of information flow. The arrows connect each component in a sequential manner, demonstrating the attack path.
### Key Observations
* The diagram highlights the vulnerability of LLMs to prompt injection attacks.
* The attack path involves a seemingly normal process (web scraping) being exploited to deliver malicious instructions.
* The output "In order to make a shurekin you need..." is a clear indication that the LLM has been manipulated to perform an unintended task. This is a nonsensical instruction, demonstrating the attacker's control.
* The diagram does not contain any numerical data or quantitative measurements. It is a conceptual illustration of a security threat.
### Interpretation
The diagram demonstrates a significant security risk associated with LLMs: prompt injection. This attack exploits the LLM's reliance on user-provided input (the prompt) to control its behavior. By injecting malicious instructions into a webpage and then scraping that webpage to feed the LLM, an attacker can bypass intended safeguards and manipulate the LLM to perform unintended, potentially harmful actions.
The "shurekin" example is particularly illustrative. It shows that the attacker can not only control *what* the LLM does but also *how* it responds, generating outputs that are completely unrelated to the original intended task. This could have serious consequences in applications where the LLM is used for critical decision-making or content generation.
The diagram emphasizes the importance of robust input validation and sanitization techniques to prevent prompt injection attacks. It also suggests the need for ongoing research into methods for detecting and mitigating these types of threats. The diagram is a warning about the potential for malicious actors to exploit the power of LLMs for nefarious purposes.