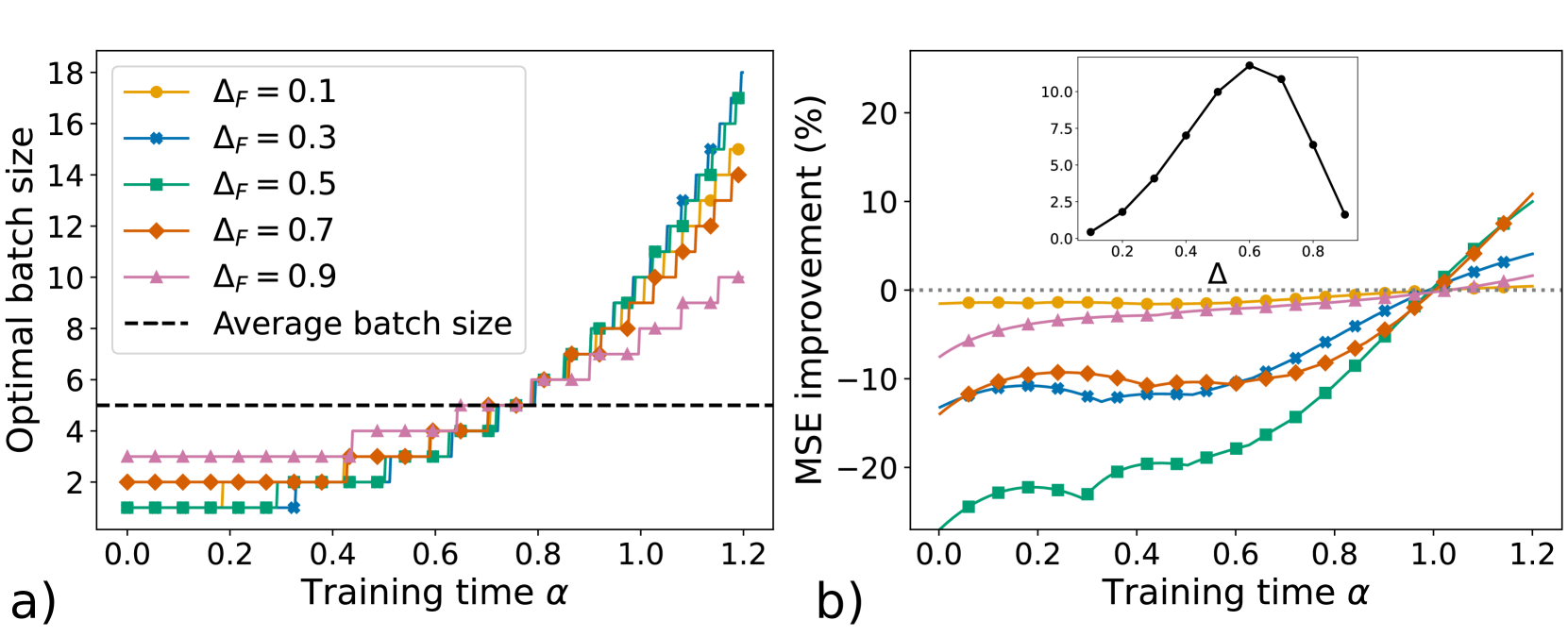
## Line Charts: Optimal Batch Size vs. MSE Improvement Over Training Time
### Overview
The image contains two line charts (a) and (b) analyzing the relationship between training time (α) and two metrics: (a) optimal batch size and (b) mean squared error (MSE) improvement. Both charts use training time (α) on the x-axis, with distinct y-axes for each metric. Multiple data series represent different ΔF values (0.1, 0.3, 0.5, 0.7, 0.9), with trends and key observations extracted below.
---
### Components/Axes
#### Chart a) Optimal Batch Size
- **X-axis**: Training time (α), ranging from 0.0 to 1.2 in increments of 0.2.
- **Y-axis**: Optimal batch size, ranging from 0 to 18 in increments of 2.
- **Legend**: Located in the top-left corner, mapping ΔF values to colors and markers:
- ΔF = 0.1: Orange circles
- ΔF = 0.3: Blue stars
- ΔF = 0.5: Green squares
- ΔF = 0.7: Orange diamonds
- ΔF = 0.9: Pink triangles
- **Average Batch Size**: Dashed black line at ~5.
#### Chart b) MSE Improvement
- **X-axis**: Training time (α), same range as chart a).
- **Y-axis**: MSE improvement (%), ranging from -20% to 20% in increments of 5%.
- **Legend**: Same as chart a), with matching colors/markers.
- **Inset Graph**: Small line chart in the top-right corner showing MSE improvement vs. Δ (ΔF) at fixed training time, peaking at Δ = 0.6.
---
### Detailed Analysis
#### Chart a) Optimal Batch Size
- **Trends**:
- All ΔF lines show **increasing optimal batch size** with training time.
- Higher ΔF values correspond to **steeper slopes** (e.g., ΔF = 0.9 reaches ~10 by α = 1.2, while ΔF = 0.1 plateaus at ~2).
- The average batch size (~5) acts as a baseline, with most lines crossing it after α ≈ 0.4.
- **Data Points**:
- ΔF = 0.1: Starts at 2 (α = 0.0), ends at ~16 (α = 1.2).
- ΔF = 0.3: Starts at 3, ends at ~14.
- ΔF = 0.5: Starts at 4, ends at ~12.
- ΔF = 0.7: Starts at 5, ends at ~10.
- ΔF = 0.9: Starts at 6, ends at ~8.
#### Chart b) MSE Improvement
- **Trends**:
- All ΔF lines show **increasing MSE improvement** with training time.
- Higher ΔF values achieve **faster and greater improvement** (e.g., ΔF = 0.9 reaches ~15% by α = 1.2, while ΔF = 0.1 stays near 0%).
- The inset graph reveals a **peak in MSE improvement at Δ = 0.6**, suggesting this ΔF value optimizes performance.
- **Data Points**:
- ΔF = 0.1: Starts at -5%, ends at ~0%.
- ΔF = 0.3: Starts at -10%, ends at ~5%.
- ΔF = 0.5: Starts at -15%, ends at ~10%.
- ΔF = 0.7: Starts at -20%, ends at ~12%.
- ΔF = 0.9: Starts at -25%, ends at ~15%.
---
### Key Observations
1. **Positive Correlation**: Higher ΔF values consistently yield larger optimal batch sizes and better MSE improvement.
2. **Divergence in Performance**: ΔF = 0.9 outperforms others in both metrics, while ΔF = 0.1 underperforms.
3. **Optimal ΔF**: The inset graph in chart b) identifies Δ = 0.6 as the peak for MSE improvement, aligning with ΔF = 0.6 in chart a).
4. **Average Batch Size**: The dashed line (~5) suggests a typical batch size, but optimal values vary significantly with ΔF.
---
### Interpretation
- **Training Dynamics**: As training progresses (α increases), larger batch sizes and better MSE improvement are achieved, particularly for higher ΔF values. This implies that ΔF influences both computational efficiency (batch size) and model performance (MSE).
- **Critical ΔF Value**: The peak at Δ = 0.6 in the inset graph highlights a potential sweet spot for balancing ΔF and training time to maximize MSE improvement. This could inform hyperparameter tuning strategies.
- **Trade-offs**: While higher ΔF improves performance, it may require larger batch sizes, which could impact computational resources. The average batch size (~5) provides a reference for typical scenarios, but optimal configurations depend on ΔF.
This analysis underscores the importance of ΔF in optimizing training efficiency and model accuracy, with ΔF = 0.6 emerging as a critical parameter for MSE improvement.