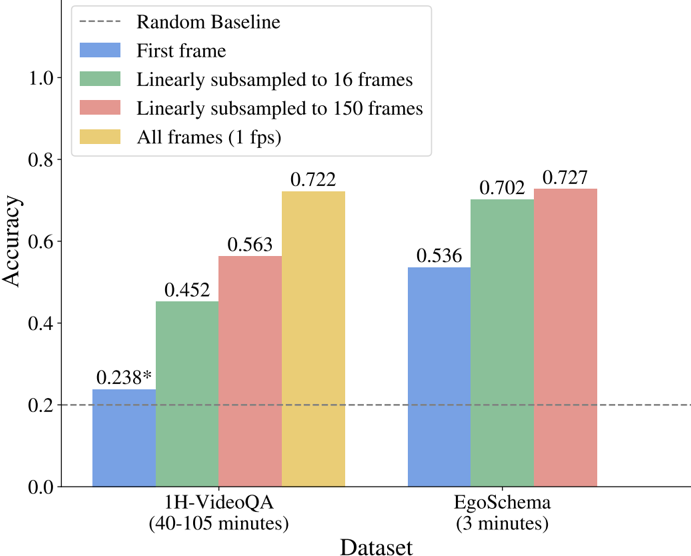
## Bar Chart: Accuracy Comparison of Frame Sampling Methods on Video QA Datasets
### Overview
This is a grouped bar chart comparing the accuracy of four different frame sampling strategies on two video question-answering (Video QA) datasets of different durations. The chart evaluates how the amount of visual information (number of frames) impacts model performance.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:** Labeled "Accuracy". Scale ranges from 0.0 to 1.0, with major tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-Axis:** Labeled "Dataset". Contains two categorical groups:
1. `1H-VideoQA (40-105 minutes)`
2. `EgoSchema (3 minutes)`
* **Legend:** Located in the top-left corner of the plot area. Defines four data series by color and label:
* **Blue:** `First frame`
* **Green:** `Linearly subsampled to 16 frames`
* **Red/Pink:** `Linearly subsampled to 150 frames`
* **Yellow/Gold:** `All frames (1 fps)`
* **Baseline:** A horizontal dashed grey line at y=0.2, labeled `Random Baseline` in the legend.
### Detailed Analysis
**Data Series and Values:**
The chart presents accuracy scores for each sampling method on each dataset. Values are annotated directly on top of each bar.
**For the `1H-VideoQA (40-105 minutes)` dataset (left group):**
1. **First frame (Blue):** Accuracy = `0.238*` (The asterisk likely denotes a footnote or special condition not visible in the image).
2. **Linearly subsampled to 16 frames (Green):** Accuracy = `0.452`.
3. **Linearly subsampled to 150 frames (Red/Pink):** Accuracy = `0.563`.
4. **All frames (1 fps) (Yellow/Gold):** Accuracy = `0.722`.
**For the `EgoSchema (3 minutes)` dataset (right group):**
1. **First frame (Blue):** Accuracy = `0.536`.
2. **Linearly subsampled to 16 frames (Green):** Accuracy = `0.702`.
3. **Linearly subsampled to 150 frames (Red/Pink):** Accuracy = `0.727`.
4. **All frames (1 fps) (Yellow/Gold):** This bar is **absent** for the EgoSchema dataset.
**Trend Verification:**
* **1H-VideoQA Trend:** There is a clear, consistent upward trend. Accuracy increases monotonically as more frames are used: First frame (lowest) < 16 frames < 150 frames < All frames (highest).
* **EgoSchema Trend:** A similar upward trend is observed from First frame to 16 frames to 150 frames. The trend cannot be verified for "All frames" as the data point is missing.
### Key Observations
1. **Performance vs. Frame Count:** For both datasets, using more frames (from 1 to 16 to 150) leads to significantly higher accuracy. The "All frames" method yields the highest accuracy on the 1H-VideoQA dataset.
2. **Dataset Difficulty:** The `1H-VideoQA` dataset appears to be more challenging. Its highest accuracy (0.722 with all frames) is comparable to the mid-tier performance on the shorter `EgoSchema` dataset (0.702 with 16 frames). The random baseline (0.2) is only marginally outperformed by the "First frame" method on 1H-VideoQA.
3. **Missing Data Point:** The "All frames (1 fps)" condition is not reported for the `EgoSchema` dataset. This could be due to computational constraints (processing all frames for many videos) or a different experimental setup.
4. **Diminishing Returns:** On the `EgoSchema` dataset, the accuracy gain from 16 frames (0.702) to 150 frames (0.727) is smaller (+0.025) than the gain from 1 frame to 16 frames (+0.166), suggesting potential diminishing returns with very high frame counts on shorter videos.
### Interpretation
The data demonstrates a strong positive correlation between the density of temporal visual information (number of sampled frames) and the accuracy of Video QA models. This suggests that understanding video content for question answering benefits substantially from observing more moments within the video, rather than relying on a single frame or sparse sampling.
The stark difference in baseline performance between the two datasets indicates that `1H-VideoQA`, with its much longer duration (40-105 minutes vs. 3 minutes), is a more complex task. The "First frame" baseline performs poorly here, implying that critical information for answering questions is distributed throughout the long video and cannot be captured from a single snapshot. In contrast, for the shorter `EgoSchema` videos, a single frame provides a much stronger starting point (0.536 accuracy).
The absence of the "All frames" result for `EgoSchema` is a notable gap. If included, it might show whether the performance ceiling is reached with 150 frames for short videos or if further gains are possible. Overall, the chart argues for the importance of dense temporal sampling in video understanding models, especially for long-form content.