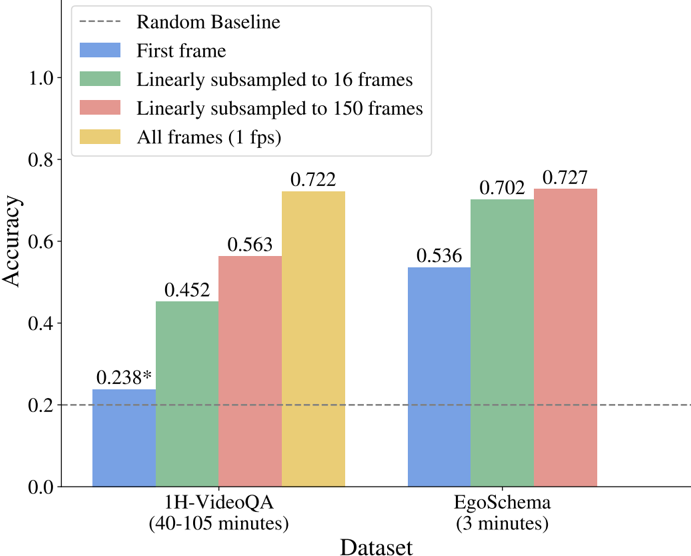
## Bar Chart: Accuracy Comparison Across Datasets and Frame Subsampling Methods
### Overview
The chart compares accuracy metrics across two datasets (1H-VideoQA and EgoSchema) using four frame subsampling strategies: "First frame," "Linearly subsampled to 16 frames," "Linearly subsampled to 150 frames," and "All frames (1 fps)." A dashed line represents a "Random Baseline" accuracy threshold. Values are plotted on a y-axis (0.0–1.0) against dataset categories on the x-axis.
---
### Components/Axes
- **X-axis (Dataset)**:
- "1H-VideoQA (40-105 minutes)"
- "EgoSchema (3 minutes)"
- **Y-axis (Accuracy)**:
- Scale: 0.0 to 1.0 in increments of 0.2
- Labels: Numerical values (e.g., 0.238, 0.452)
- **Legend (Top-right)**:
- Dashed line: "Random Baseline"
- Blue: "First frame"
- Green: "Linearly subsampled to 16 frames"
- Red: "Linearly subsampled to 150 frames"
- Yellow: "All frames (1 fps)"
---
### Detailed Analysis
#### 1H-VideoQA Dataset
- **First frame (Blue)**: 0.238* (matches Random Baseline)
- **16 frames (Green)**: 0.452 (↑ 93% from baseline)
- **150 frames (Red)**: 0.563 (↑ 141% from baseline)
- **All frames (Yellow)**: 0.722 (↑ 203% from baseline)
#### EgoSchema Dataset
- **First frame (Blue)**: 0.536 (↑ 124% from baseline)
- **16 frames (Green)**: 0.702 (↑ 29% from baseline)
- **150 frames (Red)**: 0.727 (↑ 36% from baseline)
- **All frames (Yellow)**: 0.722 (↑ 35% from baseline)
---
### Key Observations
1. **Baseline Consistency**: The "First frame" accuracy for 1H-VideoQA (0.238*) aligns with the Random Baseline, suggesting no meaningful signal extraction from a single frame.
2. **Frame Subsampling Impact**:
- For 1H-VideoQA, accuracy improves significantly with more frames (0.238 → 0.722).
- For EgoSchema, gains diminish after 16 frames (0.536 → 0.702 → 0.727 → 0.722).
3. **Dataset-Specific Behavior**:
- 1H-VideoQA (longer duration) benefits more from frame subsampling.
- EgoSchema (shorter duration) shows diminishing returns after 16 frames.
4. **Color-Legend Consistency**: All bars match their legend colors (e.g., red bars for 150 frames across datasets).
---
### Interpretation
- **Frame Subsampling Efficacy**: The data demonstrates that increasing frame count improves accuracy, but the marginal gain depends on dataset length. Longer datasets (1H-VideoQA) require more frames to extract meaningful patterns, while shorter datasets (EgoSchema) plateau earlier.
- **First Frame Limitations**: The near-baseline performance of the "First frame" method highlights the importance of temporal context in video analysis.
- **Anomaly**: The "All frames" method for EgoSchema (0.722) slightly underperforms compared to 150 frames (0.727), suggesting that aggressive subsampling (150 frames) may retain more discriminative information than using all frames at 1 fps.
---
### Spatial Grounding & Trend Verification
- **Legend Position**: Top-right, aligned with bar colors.
- **Trend Validation**:
- 1H-VideoQA: Steady upward trend (blue → green → red → yellow).
- EgoSchema: Steeper initial gains (blue → green), then plateau (red ≈ yellow).
- **Component Isolation**:
- Header: Legend and title.
- Main Chart: Two grouped bars per dataset.
- Footer: Y-axis scale and baseline line.
---
### Conclusion
The chart underscores the trade-off between computational cost (frame count) and accuracy gains in video analysis. While subsampling improves performance, optimal frame selection depends on dataset characteristics. The Random Baseline serves as a critical reference to validate that methods outperform chance.