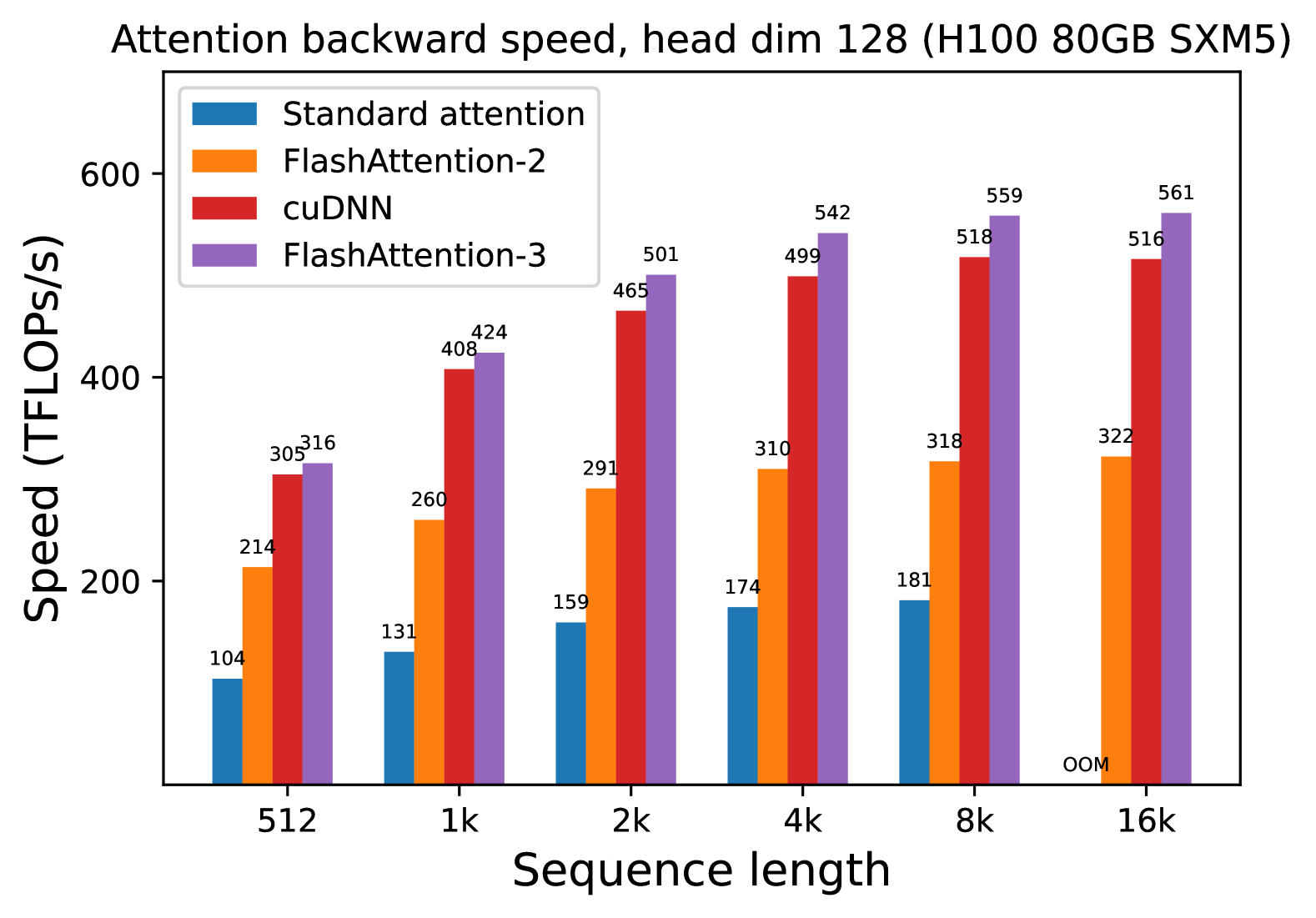
# Technical Data Extraction: Attention Backward Speed Benchmark
## 1. Document Header
* **Title:** Attention backward speed, head dim 128 (H100 80GB SXM5)
* **Subject:** Performance benchmarking of different attention mechanisms on NVIDIA H100 GPU hardware.
## 2. Chart Metadata and Structure
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis Label:** Speed (TFLOPS/s)
* **Y-Axis Scale:** Linear, ranging from 0 to 600 with major markers at [200, 400, 600].
* **X-Axis Label:** Sequence length
* **X-Axis Categories:** 512, 1k, 2k, 4k, 8k, 16k.
* **Legend Location:** Top-left [x: ~0.15, y: ~0.85].
## 3. Legend and Series Identification
The chart compares four distinct implementations, color-coded as follows:
1. **Standard attention** (Blue): Represents the baseline implementation.
2. **FlashAttention-2** (Orange): An optimized attention algorithm.
3. **cuDNN** (Red): NVIDIA's Deep Neural Network library implementation.
4. **FlashAttention-3** (Purple): The latest iteration of the FlashAttention algorithm.
## 4. Data Table Reconstruction
The following table transcribes the numerical values (TFLOPS/s) displayed above each bar in the chart.
| Sequence Length | Standard attention (Blue) | FlashAttention-2 (Orange) | cuDNN (Red) | FlashAttention-3 (Purple) |
| :--- | :--- | :--- | :--- | :--- |
| **512** | 104 | 214 | 305 | 316 |
| **1k** | 131 | 260 | 408 | 424 |
| **2k** | 159 | 291 | 465 | 501 |
| **4k** | 174 | 310 | 499 | 542 |
| **8k** | 181 | 318 | 518 | 559 |
| **16k** | OOM* | 322 | 516 | 561 |
*\*OOM: Out of Memory*
## 5. Trend Analysis and Observations
### Component Isolation: Performance Trends
* **Standard attention (Blue):** Shows a slow upward slope from 104 to 181 TFLOPS/s as sequence length increases, but fails at 16k due to memory constraints (OOM). It is consistently the lowest-performing method.
* **FlashAttention-2 (Orange):** Shows a steady upward slope, roughly doubling the performance of standard attention across all sequence lengths, peaking at 322 TFLOPS/s.
* **cuDNN (Red):** Shows a sharp upward slope between 512 and 2k, then plateaus/levels off between 4k and 16k, maintaining a high performance around 516-518 TFLOPS/s.
* **FlashAttention-3 (Purple):** Shows the steepest and highest upward slope. It consistently outperforms all other methods. It continues to scale effectively even at 16k, reaching the highest recorded value of 561 TFLOPS/s.
### Key Findings
* **Scaling:** All methods show improved TFLOPS/s as sequence length increases, indicating better hardware utilization at higher workloads.
* **Efficiency:** FlashAttention-3 provides a significant performance boost over FlashAttention-2 (approx. 1.5x to 1.7x improvement depending on sequence length).
* **Stability:** While cuDNN is highly competitive, FlashAttention-3 maintains a lead of approximately 7-8% at the highest sequence lengths (8k-16k).
* **Memory Management:** Only the "Standard attention" implementation encountered an Out of Memory (OOM) error at the 16k sequence length, highlighting the memory efficiency of the other three optimized kernels.