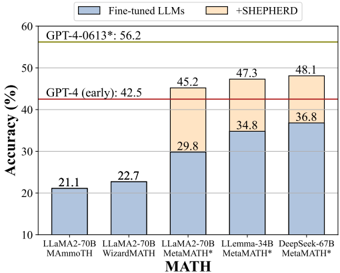
## Bar Chart: Accuracy of LLMs on MATH Dataset
### Overview
The image is a bar chart comparing the accuracy of various Large Language Models (LLMs) on the MATH dataset. The chart shows the accuracy of fine-tuned LLMs and the improvement achieved by adding "+SHEPHERD". It also includes horizontal lines indicating the performance of GPT-4 models.
### Components/Axes
* **X-axis:** MATH (Categories of LLMs: LLaMA2-70B MAmmoTH, LLaMA2-70B WizardMATH, LLaMA2-70B MetaMATH, LLemma-34B MetaMATH*, DeepSeek-67B MetaMATH*)
* **Y-axis:** Accuracy (%) (Scale from 10 to 60, with increments of 10)
* **Legend:**
* Blue: Fine-tuned LLMs
* Orange: +SHEPHERD
* **Horizontal Lines:**
* Red: GPT-4 (early): 42.5
* Green: GPT-4-0613*: 56.2
### Detailed Analysis
The chart presents the accuracy of different LLMs on the MATH dataset, with and without the addition of "+SHEPHERD".
* **LLaMA2-70B MAmmoTH:** Accuracy of fine-tuned LLM is approximately 21.1%.
* **LLaMA2-70B WizardMATH:** Accuracy of fine-tuned LLM is approximately 22.7%.
* **LLaMA2-70B MetaMATH:** Accuracy of fine-tuned LLM is approximately 29.8%. With +SHEPHERD, the accuracy increases to approximately 45.2%.
* **LLemma-34B MetaMATH*:** Accuracy of fine-tuned LLM is approximately 34.8%. With +SHEPHERD, the accuracy increases to approximately 47.3%.
* **DeepSeek-67B MetaMATH*:** Accuracy of fine-tuned LLM is approximately 36.8%. With +SHEPHERD, the accuracy increases to approximately 48.1%.
The horizontal lines indicate the performance of GPT-4 models:
* GPT-4 (early): 42.5%
* GPT-4-0613*: 56.2%
### Key Observations
* The addition of "+SHEPHERD" consistently improves the accuracy of the LLMs on the MATH dataset.
* The DeepSeek-67B MetaMATH* model achieves the highest accuracy among the tested models with +SHEPHERD.
* The performance of GPT-4-0613* significantly surpasses all other models shown in the chart.
### Interpretation
The data suggests that fine-tuning LLMs can improve their performance on the MATH dataset, and the addition of "+SHEPHERD" further enhances their accuracy. The performance of GPT-4 models serves as a benchmark, indicating the potential for further improvement in LLM performance on mathematical reasoning tasks. The chart highlights the effectiveness of "+SHEPHERD" in boosting the accuracy of LLMs, particularly for the MetaMATH variants. The DeepSeek-67B MetaMATH* model, with +SHEPHERD, shows the most promising results among the tested models, approaching the performance of GPT-4 (early).