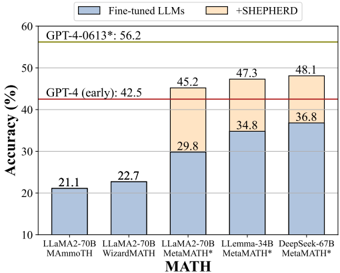
## Bar Chart: Model Accuracy on MATH Dataset
### Overview
The chart compares the accuracy of various large language models (LLMs) on the MATH dataset, with and without the "+SHEPHERD" enhancement. It includes two horizontal reference lines: one at 42.5% labeled "GPT-4 (early)" and another at 56.2% labeled "GPT-4-0613*".
### Components/Axes
- **X-axis**: Model names (LLama2-70B MAmmoTH, LLama2-70B WizardMATH, LLama2-70B MetaMATH*, LLeMma-34B MetaMATH*, DeepSeek-67B MetaMATH*).
- **Y-axis**: Accuracy (%) ranging from 10% to 60%.
- **Legend**:
- Blue: "Fine-tuned LLMs" (base accuracy).
- Orange: "+SHEPHERD" (additional accuracy from the enhancement).
- **Horizontal Lines**:
- Red line at 42.5% (GPT-4 early).
- Green line at 56.2% (GPT-4-0613*).
### Detailed Analysis
- **LLama2-70B MAmmoTH**:
- Base accuracy: 21.1% (blue).
- +SHEPHERD: 22.7% (orange).
- **LLama2-70B WizardMATH**:
- Base accuracy: 22.7% (blue).
- +SHEPHERD: 29.8% (orange).
- **LLama2-70B MetaMATH***:
- Base accuracy: 34.8% (blue).
- +SHEPHERD: 45.2% (orange).
- **LLeMma-34B MetaMATH***:
- Base accuracy: 34.8% (blue).
- +SHEPHERD: 47.3% (orange).
- **DeepSeek-67B MetaMATH***:
- Base accuracy: 36.8% (blue).
- +SHEPHERD: 48.1% (orange).
### Key Observations
1. **SHEPHERD Enhancement**: All models show improved accuracy when combined with SHEPHERD, with the largest gains in LLama2-70B WizardMATH (+7.1%) and DeepSeek-67B MetaMATH* (+11.3%).
2. **GPT-4 Benchmarks**:
- GPT-4 (early) at 42.5% is surpassed by all models with SHEPHERD.
- GPT-4-0613* at 56.2% remains the highest accuracy, but only DeepSeek-67B MetaMATH* (+SHEPHERD) approaches this value (48.1%).
3. **Model Performance**:
- LLama2-70B MAmmoTH and WizardMATH have the lowest base accuracies but show moderate improvements with SHEPHERD.
- LLeMma-34B and DeepSeek-67B MetaMATH* achieve the highest combined accuracies.
### Interpretation
The chart demonstrates that the "+SHEPHERD" enhancement significantly boosts the performance of all tested models on the MATH dataset. While GPT-4-0613* remains the top performer, the integration of SHEPHERD with models like DeepSeek-67B MetaMATH* brings their accuracy closer to GPT-4's baseline. This suggests that SHEPHERD is a critical component for improving mathematical reasoning capabilities in LLMs, particularly for models with lower initial performance. The data highlights the importance of hybrid approaches (fine-tuning + external enhancements) in advancing LLM accuracy for complex tasks like mathematical problem-solving.