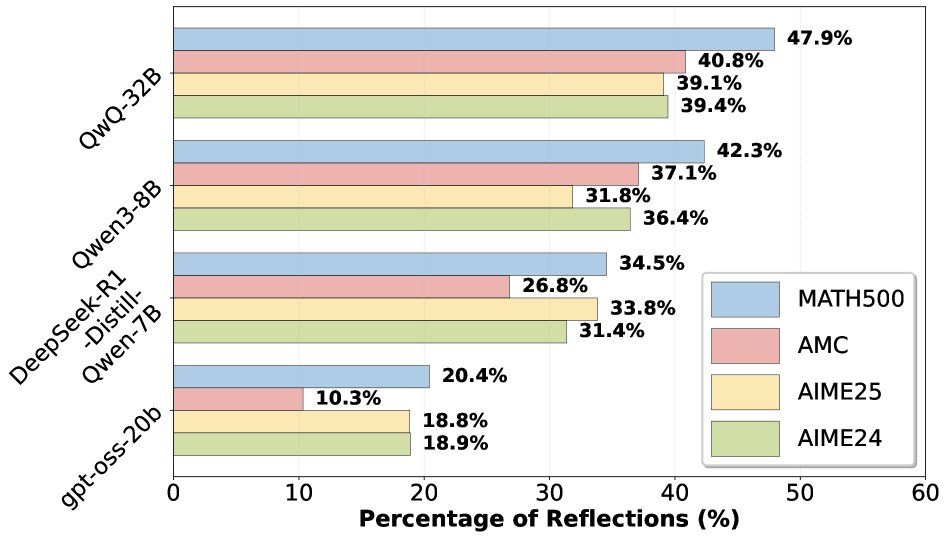
## Bar Chart: Percentage of Reflections for Different Models
### Overview
The image is a horizontal bar chart comparing the "Percentage of Reflections" for different language models across four datasets: MATH500, AMC, AIME25, and AIME24. The models are listed on the vertical axis, and the percentage of reflections is on the horizontal axis.
### Components/Axes
* **Vertical Axis (Y-Axis):** Lists the language models:
* QwQ-32B
* Qwen3-8B
* DeepSeek-R1-Distill-Qwen-7B
* gpt-oss-20b
* **Horizontal Axis (X-Axis):** "Percentage of Reflections (%)" ranging from 0 to 60, with increments of 10.
* **Legend (Bottom-Right):**
* Blue: MATH500
* Red: AMC
* Yellow: AIME25
* Green: AIME24
### Detailed Analysis
Here's a breakdown of the percentage of reflections for each model and dataset:
* **QwQ-32B:**
* MATH500 (Blue): 47.9%
* AMC (Red): 40.8%
* AIME25 (Yellow): 39.1%
* AIME24 (Green): 39.4%
* **Qwen3-8B:**
* MATH500 (Blue): 42.3%
* AMC (Red): 37.1%
* AIME25 (Yellow): 31.8%
* AIME24 (Green): 36.4%
* **DeepSeek-R1-Distill-Qwen-7B:**
* MATH500 (Blue): 34.5%
* AMC (Red): 26.8%
* AIME25 (Yellow): 33.8%
* AIME24 (Green): 31.4%
* **gpt-oss-20b:**
* MATH500 (Blue): 20.4%
* AMC (Red): 10.3%
* AIME25 (Yellow): 18.8%
* AIME24 (Green): 18.9%
### Key Observations
* **MATH500 Performance:** MATH500 generally has the highest percentage of reflections across all models, indicated by the blue bars being the longest for each model.
* **gpt-oss-20b Performance:** The gpt-oss-20b model consistently shows the lowest percentage of reflections across all datasets.
* **Model Ranking:** QwQ-32B generally outperforms the other models in terms of percentage of reflections.
### Interpretation
The bar chart illustrates the performance of different language models in terms of their "Percentage of Reflections" on various datasets. A higher percentage might indicate a greater ability to generate relevant or reflective responses, but this interpretation depends on the specific context and definition of "reflections."
The data suggests that:
* QwQ-32B is the most reflective model among those tested.
* gpt-oss-20b is the least reflective model.
* The MATH500 dataset elicits the highest percentage of reflections across all models, suggesting it may be more conducive to reflective responses compared to the other datasets.
* The performance differences between models and datasets could be attributed to factors such as model architecture, training data, and the nature of the questions or prompts within each dataset.