\n
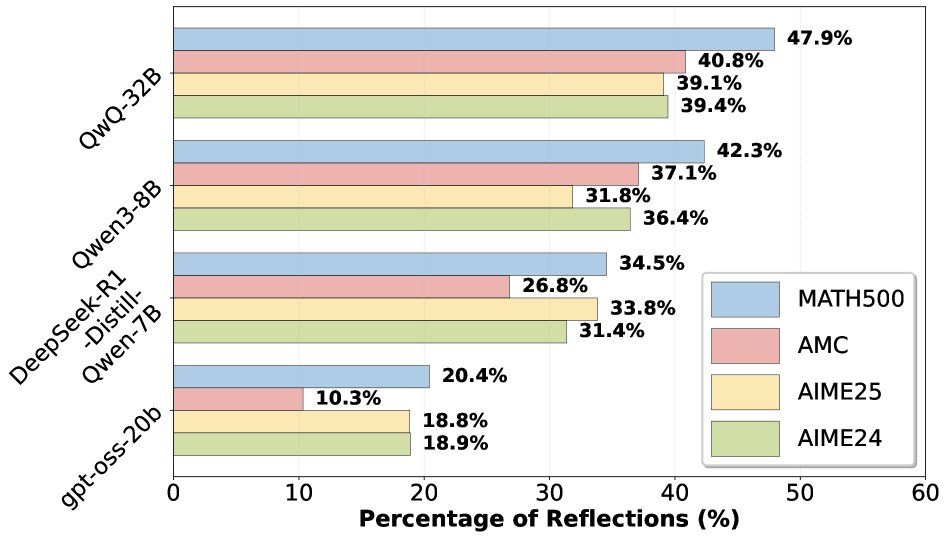
## Horizontal Bar Chart: Percentage of Reflections for Different Models
### Overview
This is a horizontal bar chart comparing the percentage of reflections generated by several language models on a specific task. The chart displays the performance of five models: QwQ-32B, Qwen-3-8B, DeepSeek-R1-Distil-Qwen-7B, and gpt-oss-20b, across four evaluation metrics: MATH500, AMC, AIME25, and AIME24.
### Components/Axes
* **Y-axis:** Lists the language models: QwQ-32B, Qwen-3-8B, DeepSeek-R1-Distil-Qwen-7B, and gpt-oss-20b.
* **X-axis:** Represents the "Percentage of Reflections (%)", ranging from 0 to 60.
* **Legend (Top-Right):** Identifies the four evaluation metrics using color-coding:
* MATH500 (Blue)
* AMC (Red)
* AIME25 (Yellow)
* AIME24 (Green)
### Detailed Analysis
The chart consists of bars grouped for each model, with each bar representing a different evaluation metric.
* **QwQ-32B:**
* MATH500: Approximately 47.9%
* AMC: Approximately 40.8%
* AIME25: Approximately 39.4%
* **Qwen-3-8B:**
* MATH500: Approximately 42.3%
* AMC: Approximately 37.1%
* AIME25: Approximately 31.8%
* AIME24: Approximately 36.4%
* **DeepSeek-R1-Distil-Qwen-7B:**
* MATH500: Approximately 34.5%
* AMC: Approximately 26.8%
* AIME25: Approximately 33.8%
* AIME24: Approximately 31.4%
* **gpt-oss-20b:**
* MATH500: Approximately 20.4%
* AMC: Approximately 10.3%
* AIME25: Approximately 18.9%
* AIME24: Approximately 18.8%
### Key Observations
* QwQ-32B consistently demonstrates the highest percentage of reflections across all evaluation metrics.
* gpt-oss-20b consistently shows the lowest percentage of reflections across all evaluation metrics.
* MATH500 generally has the highest reflection percentage for each model compared to other metrics.
* AMC generally has the lowest reflection percentage for each model compared to other metrics.
* The differences in reflection percentages between AIME25 and AIME24 are relatively small for each model.
### Interpretation
The data suggests that QwQ-32B is the most effective model at generating reflections based on these evaluation metrics, while gpt-oss-20b is the least effective. The consistent performance differences across metrics indicate that the models have inherent strengths and weaknesses in their ability to handle these types of tasks. The higher reflection percentages for MATH500 suggest that the models perform better on tasks related to mathematical reasoning, while the lower percentages for AMC suggest they struggle more with problems from the American Mathematics Competitions. The relatively small differences between AIME25 and AIME24 suggest that the difficulty level between these two metrics is similar for the models. This chart provides a comparative analysis of model performance, highlighting areas where each model excels or needs improvement. The term "reflections" in this context likely refers to the model's ability to generate correct or relevant responses to prompts or questions related to the evaluation metrics.