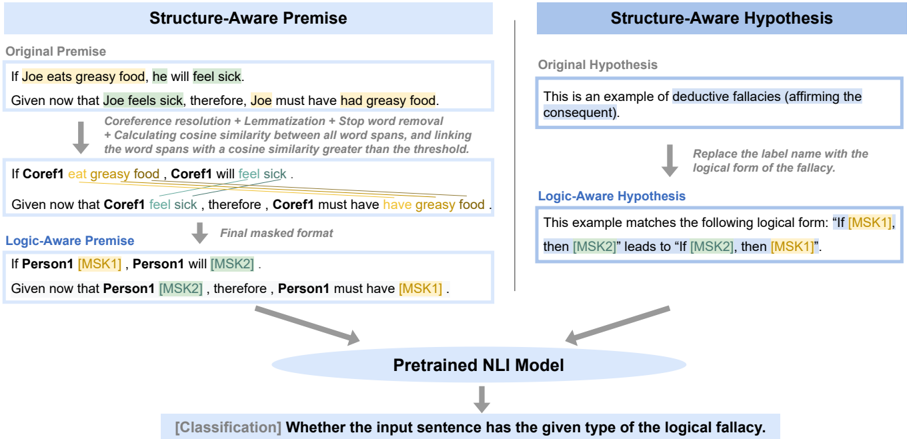
## Diagram: Structure-Aware Premise and Hypothesis Flow
### Overview
The image presents a diagram illustrating the transformation of an original premise and hypothesis into logic-aware forms using a structure-aware approach. It shows the steps involved in processing the premise and hypothesis, including coreference resolution, lemmatization, and masking, before feeding them into a pretrained NLI model for classification.
### Components/Axes
* **Titles:** "Structure-Aware Premise" (left), "Structure-Aware Hypothesis" (right)
* **Sections:**
* Original Premise/Hypothesis
* Intermediate Processing Steps (Coreference resolution, etc.)
* Logic-Aware Premise/Hypothesis
* Pretrained NLI Model
* Classification Output
* **Arrows:** Indicate the flow of information and transformations.
### Detailed Analysis or ### Content Details
**1. Structure-Aware Premise (Left Side):**
* **Original Premise:**
* "If Joe eats greasy food, he will feel sick." (Highlighted: "eats greasy food" in yellow, "feel sick" in light green)
* "Given now that Joe feels sick, therefore, Joe must have had greasy food." (Highlighted: "feels sick" in light green, "had greasy food" in yellow)
* **Processing Steps:**
* "Coreference resolution + Lemmatization + Stop word removal"
* "+ Calculating cosine similarity between all word spans, and linking the word spans with a cosine similarity greater than the threshold."
* **Intermediate Premise:**
* "If Coref1 eat greasy food, Coref1 will feel sick." (Highlighted: "eat greasy food" in yellow, "feel sick" in light green)
* "Given now that Coref1 feel sick, therefore, Coref1 must have have greasy food." (Highlighted: "feel sick" in light green, "have greasy food" in yellow)
* Lines connect "eat greasy food" to "have greasy food" and "feel sick" to "feel sick".
* **Logic-Aware Premise:**
* "If Person1 [MSK1], Person1 will [MSK2]."
* "Given now that Person1 [MSK2], therefore, Person1 must have [MSK1]."
**2. Structure-Aware Hypothesis (Right Side):**
* **Original Hypothesis:**
* "This is an example of deductive fallacies (affirming the consequent)."
* **Processing Step:**
* "Replace the label name with the logical form of the fallacy."
* **Logic-Aware Hypothesis:**
* "This example matches the following logical form: "If [MSK1], then [MSK2]" leads to "If [MSK2], then [MSK1]"." (Highlighted: "[MSK1]" in yellow, "[MSK2]" in light blue)
**3. Pretrained NLI Model (Bottom Center):**
* **Text:** "Pretrained NLI Model"
* **Input:** Arrows from both Logic-Aware Premise and Logic-Aware Hypothesis point to this block.
* **Output:** An arrow points downwards from this block.
**4. Classification Output (Bottom):**
* **Text:** "[Classification] Whether the input sentence has the given type of the logical fallacy."
### Key Observations
* The diagram illustrates a process of transforming natural language premises and hypotheses into a masked, logic-aware format.
* Coreference resolution, lemmatization, and cosine similarity calculations are used to identify relationships between words and phrases.
* The masked format replaces specific phrases with generic placeholders like "[MSK1]" and "[MSK2]".
* The transformed premise and hypothesis are fed into a pretrained NLI model for classification.
### Interpretation
The diagram describes a method for analyzing logical fallacies in natural language. The key idea is to convert the original statements into a more structured, logic-aware representation before feeding them to a machine learning model. This involves identifying coreferences, simplifying the language, and masking specific parts of the sentence. By doing so, the model can focus on the underlying logical structure rather than the specific words used. The NLI model then classifies whether the input sentence exhibits a particular type of logical fallacy. The highlighting of phrases and the connecting lines visually emphasize the relationships and transformations occurring during the process.