# Technical Document Extraction: NetFlow Dataset Generation Pipeline
## 1. Document Overview
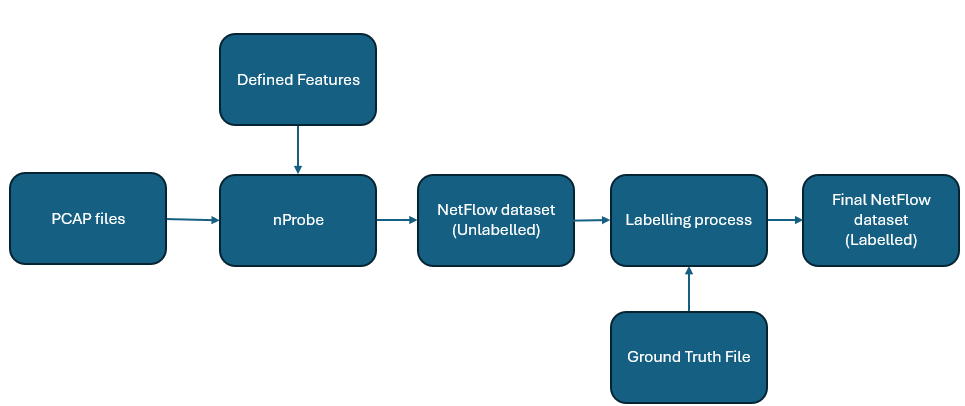
This image is a technical flow diagram illustrating the sequential process of transforming raw network traffic data into a labeled NetFlow dataset. The diagram utilizes a series of dark teal rounded rectangular blocks connected by directional arrows to indicate data flow and processing stages.
## 2. Component Isolation and Transcription
The diagram is organized into a primary horizontal pipeline with two vertical input branches.
### A. Primary Horizontal Pipeline (Left to Right)
This represents the core transformation stages of the data.
1. **PCAP files**: The initial input source containing raw packet capture data.
2. **nProbe**: The processing engine that ingests the raw files.
3. **NetFlow dataset (Unlabelled)**: The intermediate output consisting of flow records without categorical labels.
4. **Labelling process**: The functional stage where metadata or ground truth is applied to the records.
5. **Final NetFlow dataset (Labelled)**: The terminal output of the pipeline, ready for machine learning or analysis.
### B. Vertical Input Branches
These blocks provide necessary parameters or reference data to the primary pipeline.
* **Defined Features**: (Top-down input to *nProbe*) Specifies the specific attributes or metrics to be extracted from the PCAP files during the flow generation process.
* **Ground Truth File**: (Bottom-up input to *Labelling process*) Provides the authoritative reference data used to assign correct labels to the unlabelled NetFlow records.
## 3. Process Flow and Logic Description
The workflow follows a linear progression with specific injection points for configuration and validation data:
1. **Data Ingestion & Extraction**: The process begins with **PCAP files** being fed into **nProbe**. Simultaneously, **Defined Features** are provided to **nProbe** to dictate which network characteristics are captured.
2. **Flow Generation**: **nProbe** processes the raw packets based on the defined features to produce a **NetFlow dataset (Unlabelled)**.
3. **Data Annotation**: This unlabelled dataset enters the **Labelling process**. At this stage, a **Ground Truth File** is introduced. The system correlates the flow records with the ground truth data.
4. **Output**: The result of the labeling process is the **Final NetFlow dataset (Labelled)**, which contains both the network features and their corresponding classifications.
## 4. Summary of Textual Elements
| Element Type | Exact Text Content |
| :--- | :--- |
| Input Block 1 | PCAP files |
| Input Block 2 | Defined Features |
| Processor Block 1 | nProbe |
| Intermediate Output | NetFlow dataset (Unlabelled) |
| Processor Block 2 | Labelling process |
| Input Block 3 | Ground Truth File |
| Final Output | Final NetFlow dataset (Labelled) |