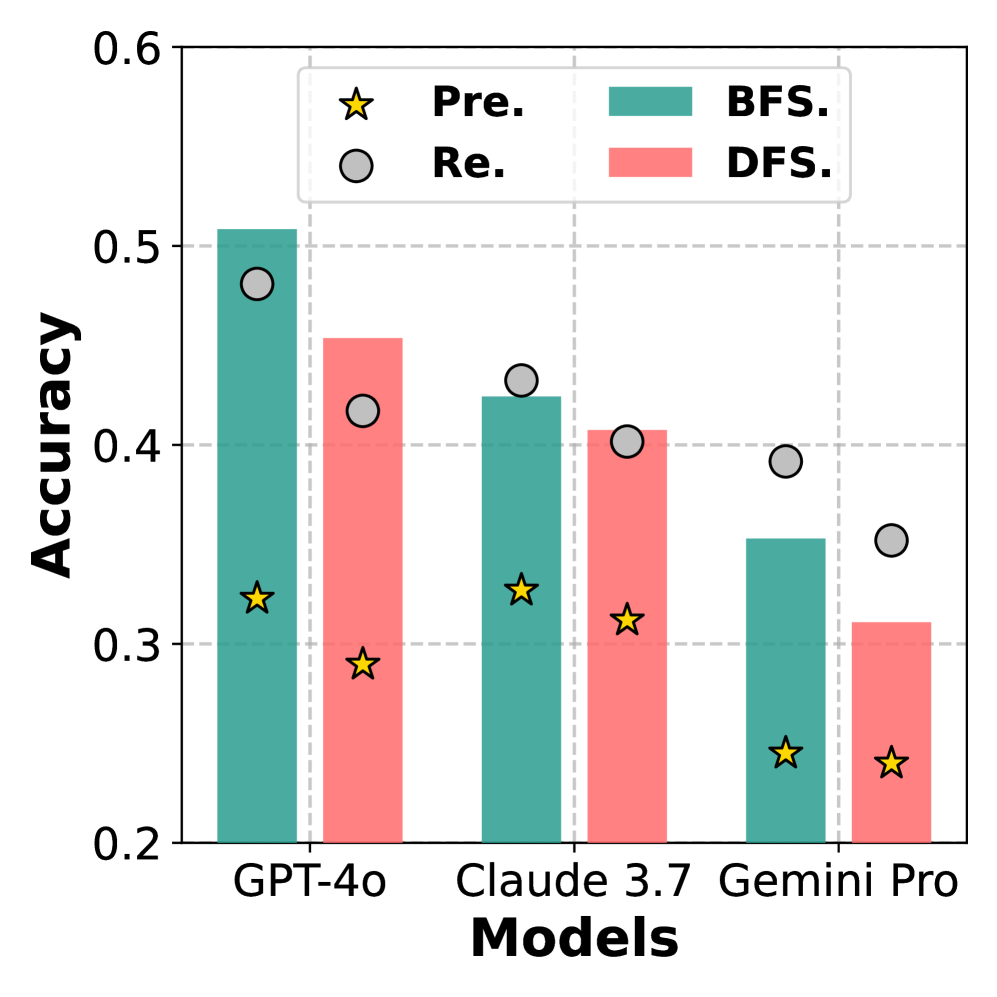
## Bar Chart: Model Accuracy Comparison
### Overview
The image is a bar chart comparing the accuracy of three language models (GPT-4o, Claude 3.7, and Gemini Pro) using two different search strategies: Breadth-First Search (BFS) and Depth-First Search (DFS). For each model, there are two bars representing the accuracy achieved with BFS (teal) and DFS (light red). Additionally, precision (Pre.) and recall (Re.) are marked with star and circle symbols, respectively, for each model and search strategy.
### Components/Axes
* **X-axis (Models):** Categorical axis representing the language models: GPT-4o, Claude 3.7, and Gemini Pro.
* **Y-axis (Accuracy):** Numerical axis representing the accuracy, ranging from 0.2 to 0.6 with increments of 0.1.
* **Legend (Top-Left):**
* Star symbol: "Pre." (Precision)
* Circle symbol: "Re." (Recall)
* Teal bar: "BFS." (Breadth-First Search)
* Light Red bar: "DFS." (Depth-First Search)
### Detailed Analysis
Here's a breakdown of the data for each model and search strategy, including precision and recall:
* **GPT-4o:**
* BFS (Teal): Accuracy is approximately 0.51. Precision (yellow star) is approximately 0.33. Recall (gray circle) is approximately 0.49.
* DFS (Light Red): Accuracy is approximately 0.45. Precision (yellow star) is approximately 0.29. Recall (gray circle) is approximately 0.42.
* **Claude 3.7:**
* BFS (Teal): Accuracy is approximately 0.43. Precision (yellow star) is approximately 0.33. Recall (gray circle) is approximately 0.43.
* DFS (Light Red): Accuracy is approximately 0.41. Precision (yellow star) is approximately 0.32. Recall (gray circle) is approximately 0.40.
* **Gemini Pro:**
* BFS (Teal): Accuracy is approximately 0.35. Precision (yellow star) is approximately 0.25. Recall (gray circle) is approximately 0.39.
* DFS (Light Red): Accuracy is approximately 0.31. Precision (yellow star) is approximately 0.24. Recall (gray circle) is approximately 0.35.
### Key Observations
* GPT-4o achieves the highest accuracy with both BFS and DFS.
* For all models, BFS generally results in higher accuracy than DFS.
* Precision is consistently lower than recall across all models and search strategies.
* Gemini Pro has the lowest accuracy among the three models for both search strategies.
### Interpretation
The chart suggests that GPT-4o is the most accurate model among the three tested, regardless of the search strategy used. The fact that BFS consistently outperforms DFS indicates that, for these models and tasks, exploring broadly before diving deep yields better results. The lower precision compared to recall suggests that the models tend to retrieve more relevant items than they retrieve exclusively relevant items, indicating a potential area for improvement in refining the search algorithms. The performance difference between the models highlights the varying capabilities of different language models in the context of these search strategies.