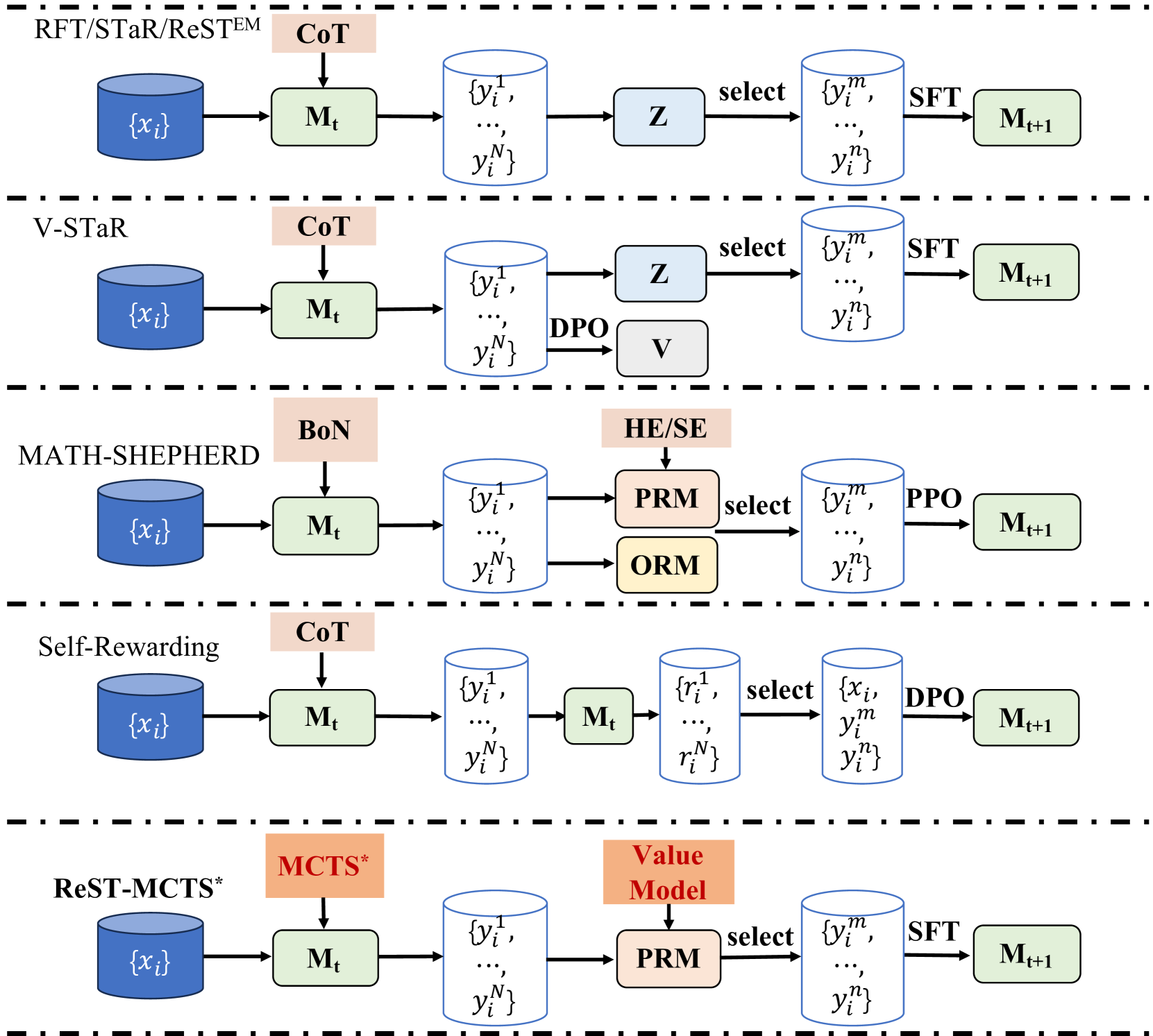
\n
## Diagram: Reinforcement Learning from Tool-use (RFT) and Related Methods
### Overview
This diagram illustrates five different reinforcement learning (RL) frameworks for tool-use, comparing their architectures and key components. Each framework is presented as a horizontal row, showing the flow of information from an initial input set {xᵢ} to an updated model Mₜ₊₁. The frameworks are RFT/STaR/ReSTEm, V-STaR, MATH-SHEPHERD, Self-Rewarding, and ReST-MCTS*. The diagram uses boxes to represent processes or models, and arrows to indicate the flow of data.
### Components/Axes
The diagram does not have traditional axes. Instead, it presents a series of interconnected components within each framework. Key components include:
* **{xᵢ}**: Input set. Represented by a blue hexagon.
* **Mₜ**: Model at time t. Represented by a light-blue rectangle.
* **CoT**: Chain of Thought.
* **BoN**: Behavior of Nature.
* **MCTS***: Monte Carlo Tree Search.
* **Z**: Selection mechanism.
* **DPO**: Direct Preference Optimization.
* **V**: Value function.
* **HE/SE**: Heuristic/Search Evaluation.
* **PRM**: Preference Reward Model.
* **ORM**: Offline Reward Model.
* **PPO**: Proximal Policy Optimization.
* **{yᵢ}**: Output set.
* **{rᵢ}**: Reward set.
* **SFT**: Supervised Fine-Tuning.
* **Mₜ₊₁**: Updated model at time t+1. Represented by a light-blue rectangle.
Horizontal dashed lines separate the five frameworks.
### Detailed Analysis / Content Details
**1. RFT/STaR/ReSTEm:**
* Input: {xᵢ}
* Process 1: Mₜ (CoT) transforms {xᵢ} into {ŷᵢ¹,…, ŷᵢᴺ}.
* Process 2: Z selects from {ŷᵢ¹,…, ŷᵢᴺ}.
* Process 3: SFT transforms the selected output into {ŷₘᵢ,…, ŷₘᵢ}.
* Output: Mₜ₊₁
**2. V-STaR:**
* Input: {xᵢ}
* Process 1: Mₜ (CoT) transforms {xᵢ} into {ŷᵢ¹,…, ŷᵢᴺ}.
* Process 2: DPO and V are applied to {ŷᵢ¹,…, ŷᵢᴺ}.
* Process 3: Z selects from {ŷᵢ¹,…, ŷᵢᴺ}.
* Process 4: SFT transforms the selected output into {ŷₘᵢ,…, ŷₘᵢ}.
* Output: Mₜ₊₁
**3. MATH-SHEPHERD:**
* Input: {xᵢ}
* Process 1: Mₜ (BoN) transforms {xᵢ} into {ŷᵢ¹,…, ŷᵢᴺ}.
* Process 2: HE/SE, PRM, and ORM are applied to {ŷᵢ¹,…, ŷᵢᴺ}.
* Process 3: PPO transforms the selected output into {ŷₘᵢ,…, ŷₘᵢ}.
* Output: Mₜ₊₁
**4. Self-Rewarding:**
* Input: {xᵢ}
* Process 1: Mₜ (CoT) transforms {xᵢ} into {ŷᵢ¹,…, ŷᵢᴺ}.
* Process 2: Mₜ calculates rewards {rᵢ¹,…, rᵢᴺ}.
* Process 3: DPO transforms the selected output into {ŷₘᵢ,…, ŷₘᵢ}.
* Output: Mₜ₊₁
**5. ReST-MCTS*:**
* Input: {xᵢ}
* Process 1: Mₜ (MCTS*) transforms {xᵢ} into {ŷᵢ¹,…, ŷᵢᴺ}.
* Process 2: Value Model and PRM are applied to {ŷᵢ¹,…, ŷᵢᴺ}.
* Process 3: SFT transforms the selected output into {ŷₘᵢ,…, ŷₘᵢ}.
* Output: Mₜ₊₁
### Key Observations
* All frameworks start with an input set {xᵢ} and a model Mₜ.
* The CoT (Chain of Thought) mechanism is used in RFT/STaR/ReSTEm, V-STaR, and Self-Rewarding.
* The selection process (Z, DPO, HE/SE, PRM, Value Model) varies across frameworks.
* SFT (Supervised Fine-Tuning) is used in RFT/STaR/ReSTEm, V-STaR, and ReST-MCTS* to generate the updated model Mₜ₊₁.
* MATH-SHEPHERD utilizes PPO (Proximal Policy Optimization) instead of SFT.
* Self-Rewarding incorporates a self-generated reward mechanism.
### Interpretation
The diagram illustrates a comparative analysis of different approaches to reinforcement learning from tool-use. Each framework attempts to improve model performance (Mₜ₊₁) by incorporating different mechanisms for generating outputs, evaluating those outputs, and updating the model. The variations in selection processes (Z, DPO, HE/SE, PRM, Value Model) and final refinement steps (SFT, PPO) highlight the diverse strategies employed to address the challenges of tool-use in RL. The inclusion of components like DPO and self-generated rewards suggests a focus on preference learning and intrinsic motivation. The diagram serves as a high-level overview of these methods, emphasizing their architectural differences rather than specific implementation details. The use of consistent notation (e.g., {xᵢ}, Mₜ, {ŷᵢ}) facilitates comparison between the frameworks. The diagram suggests that there is no single "best" approach, and the optimal framework may depend on the specific task and environment.