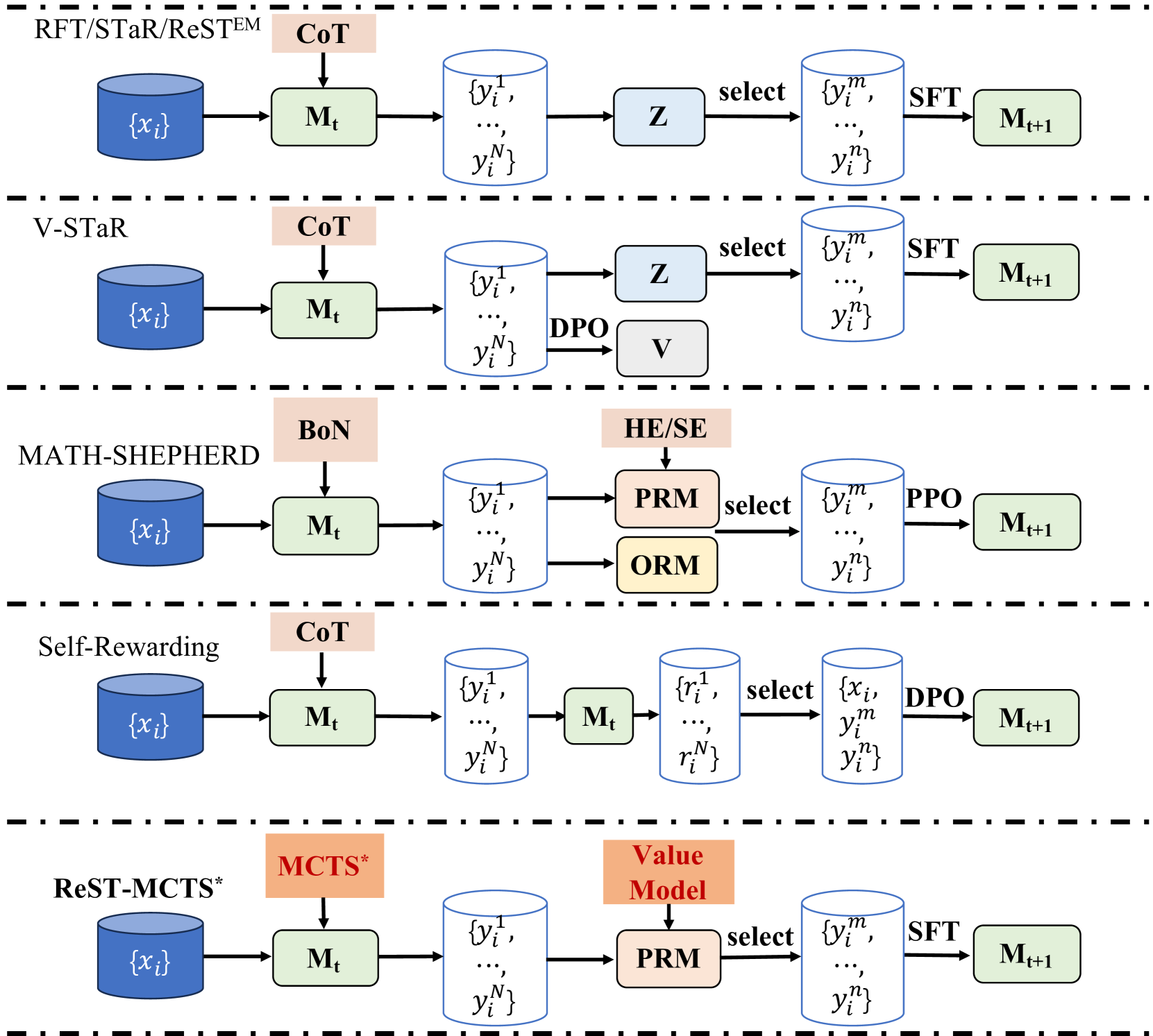
## [Diagram Type]: Machine Learning Training Pipeline Comparison
### Overview
The image is a technical diagram illustrating five distinct iterative training pipelines for machine learning models, specifically focusing on methods for improving model performance through self-generated data and reinforcement learning. The diagram is organized vertically into five horizontal sections, each separated by a thick dashed black line, representing a different method or family of methods. Each pipeline follows a similar left-to-right flow: starting with an input dataset, processing through a model, generating outputs, applying a selection or reward mechanism, and finally updating the model.
### Components/Axes
The diagram is not a chart with axes but a process flow diagram. The key components are:
* **Input Data**: Represented by a blue cylinder labeled `{x_i}`.
* **Models**: Represented by green rounded rectangles labeled `M_t` (current model) and `M_{t+1}` (updated model).
* **Generated Outputs**: Represented by white cylinders containing sets of outputs, e.g., `{y_i^1, ..., y_i^N}`.
* **Selection/Reward Mechanisms**: Represented by various colored boxes (light blue, light orange, light yellow) with labels like `Z`, `V`, `PRM`, `ORM`.
* **Training Methods**: Labeled on the arrows between components, such as `SFT`, `DPO`, `PPO`.
* **Prompting/Generation Strategies**: Labeled in light orange boxes above the first model, such as `CoT`, `BoN`, `MCTS*`.
### Detailed Analysis
The diagram details five pipelines:
**1. RFT/STaR/ReSTEM**
* **Flow**: `{x_i}` → `M_t` (with `CoT` prompting) → `{y_i^1, ..., y_i^N}` → `Z` (selection) → `{y_i^m, ..., y_i^n}` → `SFT` → `M_{t+1}`.
* **Key Components**: Uses Chain-of-Thought (`CoT`) prompting. A selection module `Z` filters the generated outputs before Supervised Fine-Tuning (`SFT`).
**2. V-STaR**
* **Flow**: `{x_i}` → `M_t` (with `CoT` prompting) → `{y_i^1, ..., y_i^N}` → splits into two paths:
* Path 1: → `Z` (selection) → `{y_i^m, ..., y_i^n}` → `SFT` → `M_{t+1}`.
* Path 2: → `DPO` → `V` (a value or verifier model).
* **Key Components**: Similar to the first pipeline but incorporates a separate `DPO` (Direct Preference Optimization) path to train a verifier model `V`.
**3. MATH-SHEPHERD**
* **Flow**: `{x_i}` → `M_t` (with `BoN` prompting) → `{y_i^1, ..., y_i^N}` → splits into two paths:
* Path 1: → `PRM` (Process Reward Model, with `HE/SE` input) → `select` → `{y_i^m, ..., y_i^n}` → `PPO` → `M_{t+1}`.
* Path 2: → `ORM` (Outcome Reward Model).
* **Key Components**: Uses Best-of-N (`BoN`) prompting. Employs both a Process Reward Model (`PRM`) and an Outcome Reward Model (`ORM`) for selection. The final training uses Proximal Policy Optimization (`PPO`). `HE/SE` likely refers to Heuristic Search or similar.
**4. Self-Rewarding**
* **Flow**: `{x_i}` → `M_t` (with `CoT` prompting) → `{y_i^1, ..., y_i^N}` → `M_t` (the same model acts as a rater) → `{r_i^1, ..., r_i^N}` (rewards) → `select` → `{x_i, y_i^m, y_i^n}` → `DPO` → `M_{t+1}`.
* **Key Components**: The model `M_t` is used twice: first to generate outputs, then to generate rewards (`r_i`) for those outputs. Selection is based on these self-generated rewards, and training is done via `DPO`.
**5. ReST-MCTS***
* **Flow**: `{x_i}` → `M_t` (with `MCTS*` prompting) → `{y_i^1, ..., y_i^N}` → `PRM` (with `Value Model` input) → `select` → `{y_i^m, ..., y_i^n}` → `SFT` → `M_{t+1}`.
* **Key Components**: Uses Monte Carlo Tree Search (`MCTS*`) for generation. A `PRM` is guided by a separate `Value Model` for selection, followed by `SFT`.
### Key Observations
* **Common Pattern**: All pipelines share a core loop: Generate → Select/Score → Train. They are all methods for **iterative self-improvement** or **reinforcement learning from self-generated data**.
* **Variations in Generation**: Prompting strategies vary: `CoT` (3 pipelines), `BoN` (1), `MCTS*` (1).
* **Variations in Selection/Reward**: Selection mechanisms range from a simple selector `Z`, to dedicated reward models (`PRM`, `ORM`), to the model rating its own outputs.
* **Variations in Training**: Final training steps include `SFT` (3 pipelines), `DPO` (2 pipelines), and `PPO` (1 pipeline).
* **Spatial Layout**: The legend/labels for each pipeline are consistently placed to the left of the flow. The prompting strategy is always in a light orange box above the first model (`M_t`). Selection/reward model boxes are placed centrally between the generation and training stages.
### Interpretation
This diagram provides a comparative taxonomy of modern techniques for training large language models (LLMs) to improve their reasoning or problem-solving abilities, particularly in domains like mathematics (hinted at by `MATH-SHEPHERD`). The overarching theme is **bootstrapping**: using the model's own outputs to create training data for its next iteration.
* **What it demonstrates**: It shows the evolution from simpler methods (like RFT/STaR which use basic selection) to more complex ones that incorporate explicit reward models (`PRM/ORM`) or advanced search algorithms (`MCTS*`). The "Self-Rewarding" pipeline is notable for its simplicity, using the model as its own evaluator.
* **Relationships**: The pipelines are not mutually exclusive; they represent a spectrum of approaches. For instance, `V-STaR` can be seen as an extension of the basic `STaR` method by adding a verifier. `MATH-SHEPHERD` and `ReST-MCTS*` represent more sophisticated, resource-intensive approaches using separate reward/value models.
* **Notable Trends**: There is a clear trend towards using more sophisticated **process-based supervision** (`PRM`) over simple outcome-based selection (`Z` or `ORM`), as process models can provide finer-grained feedback. The use of `DPO` as an alternative to `PPO` for the final training step is also a notable modern trend, as it can be more stable and efficient.
* **Underlying Message**: The diagram argues that the key to iterative improvement lies in the **quality of the selection/reward mechanism**. The choice of generation strategy (`CoT` vs. `MCTS*`) and training algorithm (`SFT` vs. `DPO` vs. `PPO`) are important, but the core innovation in these methods is how they filter or score the model's own generations to create high-quality training data.