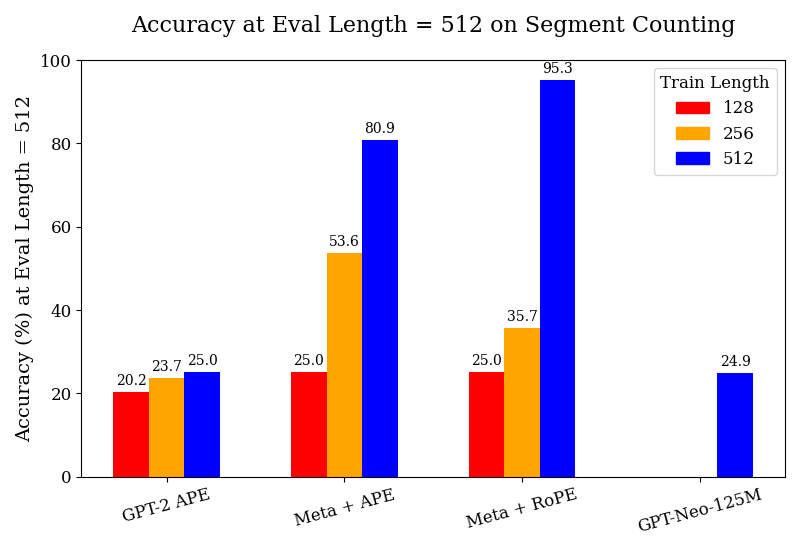
## Bar Chart: Accuracy at Eval Length = 512 on Segment Counting
### Overview
The image is a bar chart comparing the accuracy of different models (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M) on a segment counting task. The accuracy is evaluated at a fixed evaluation length of 512. The chart shows the accuracy for each model trained with different sequence lengths (128, 256, and 512).
### Components/Axes
* **Title:** Accuracy at Eval Length = 512 on Segment Counting
* **X-axis:** Model names (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M)
* **Y-axis:** Accuracy (%) at Eval Length = 512, with a scale from 0 to 100.
* **Legend (Top-Right):** Train Length, with the following colors:
* Red: 128
* Orange: 256
* Blue: 512
### Detailed Analysis
Here's a breakdown of the accuracy for each model and train length:
* **GPT-2 APE:**
* Train Length 128 (Red): 20.2%
* Train Length 256 (Orange): 23.7%
* Train Length 512 (Blue): 25.0%
* **Meta + APE:**
* Train Length 128 (Red): 25.0%
* Train Length 256 (Orange): 53.6%
* Train Length 512 (Blue): 80.9%
* **Meta + RoPE:**
* Train Length 128 (Red): 25.0%
* Train Length 256 (Orange): 35.7%
* Train Length 512 (Blue): 95.3%
* **GPT-Neo-125M:**
* Train Length 512 (Blue): 24.9%
### Key Observations
* For GPT-2 APE, accuracy increases slightly with increasing train length.
* For Meta + APE, accuracy increases significantly with increasing train length.
* For Meta + RoPE, accuracy increases dramatically with increasing train length.
* GPT-Neo-125M only has data for train length 512, and its accuracy is relatively low compared to Meta + APE and Meta + RoPE trained with the same length.
* Meta + RoPE with a train length of 512 achieves the highest accuracy (95.3%).
### Interpretation
The chart demonstrates the impact of train length on the accuracy of different models for a segment counting task. The "Meta + RoPE" model shows the most significant improvement in accuracy as the train length increases, suggesting that it benefits the most from longer training sequences. The "GPT-Neo-125M" model performs poorly compared to the other models when trained with a length of 512. The results suggest that the choice of model architecture and training length significantly affects performance on this task. The Meta + RoPE model with a train length of 512 is a clear outlier, indicating a potentially optimal configuration for this specific task and evaluation length.