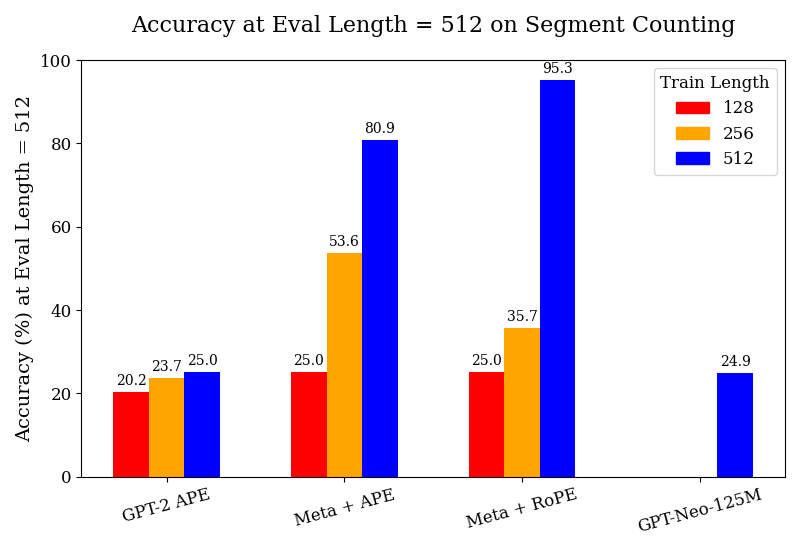
## Bar Chart: Accuracy at Eval Length = 512 on Segment Counting
### Overview
This bar chart displays the accuracy (%) at an evaluation length of 512 for segment counting, comparing different models (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M) and training lengths (128, 256, 512). The chart uses a grouped bar format, with each model having three bars representing the accuracy achieved with different training lengths.
### Components/Axes
* **Title:** Accuracy at Eval Length = 512 on Segment Counting
* **X-axis:** Model Name (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M)
* **Y-axis:** Accuracy (%) at Eval Length = 512. Scale ranges from 0 to 100.
* **Legend:**
* Train Length: 128 (Red)
* Train Length: 256 (Yellow)
* Train Length: 512 (Blue)
### Detailed Analysis
The chart consists of four groups of three bars, one group for each model.
* **GPT-2 APE:**
* Train Length 128 (Red): Approximately 20.2% accuracy.
* Train Length 256 (Yellow): Approximately 23.7% accuracy.
* Train Length 512 (Blue): Approximately 25.0% accuracy.
* Trend: Accuracy increases slightly with increasing training length.
* **Meta + APE:**
* Train Length 128 (Red): Approximately 25.0% accuracy.
* Train Length 256 (Yellow): Approximately 53.6% accuracy.
* Train Length 512 (Blue): Approximately 80.9% accuracy.
* Trend: Accuracy increases significantly with increasing training length.
* **Meta + RoPE:**
* Train Length 128 (Red): Approximately 25.0% accuracy.
* Train Length 256 (Yellow): Approximately 35.7% accuracy.
* Train Length 512 (Blue): Approximately 95.3% accuracy.
* Trend: Accuracy increases dramatically with increasing training length.
* **GPT-Neo-125M:**
* Train Length 128 (Red): Approximately 24.9% accuracy.
* Train Length 256 (Yellow): No bar present.
* Train Length 512 (Blue): Approximately 24.9% accuracy.
* Trend: Accuracy remains relatively constant with increasing training length.
### Key Observations
* The "Meta + RoPE" model consistently achieves the highest accuracy, especially with a training length of 512, reaching 95.3%.
* The "Meta + APE" model shows a substantial improvement in accuracy as the training length increases.
* GPT-2 APE and GPT-Neo-125M show minimal improvement in accuracy with increased training length.
* GPT-Neo-125M does not have a bar for Train Length 256.
### Interpretation
The data suggests that the "Meta + RoPE" model is the most effective for segment counting at an evaluation length of 512, particularly when trained with a length of 512. The significant increase in accuracy for "Meta + APE" with longer training lengths indicates that this model benefits from more training data. The relatively stable accuracy of "GPT-2 APE" and "GPT-Neo-125M" suggests that these models may have reached a performance plateau or are less sensitive to training length in this specific task. The absence of a bar for GPT-Neo-125M at Train Length 256 could indicate that this configuration was not tested or yielded no results. The chart highlights the importance of model architecture and training length in achieving high accuracy in segment counting tasks.