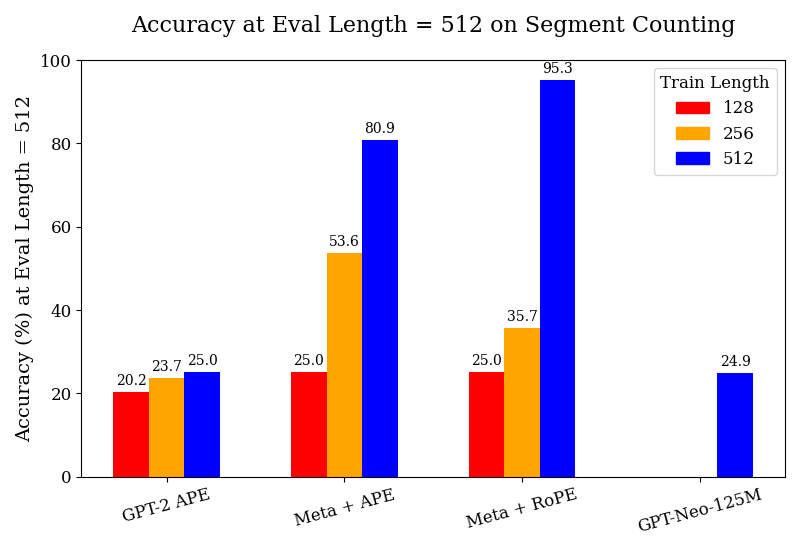
## Bar Chart: Accuracy at Eval Length = 512 on Segment Counting
### Overview
The chart compares the accuracy of four language models (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M) on a segment counting task at a fixed evaluation length of 512 tokens. Accuracy is measured across three training lengths (128, 256, 512 tokens), with results visualized as grouped bars. The highest accuracy observed is 95.3% for Meta + RoPE trained on 512 tokens.
### Components/Axes
- **X-axis**: Model configurations (GPT-2 APE, Meta + APE, Meta + RoPE, GPT-Neo-125M)
- **Y-axis**: Accuracy (%) at Eval Length = 512
- **Legend**:
- Red = Train Length = 128
- Orange = Train Length = 256
- Blue = Train Length = 512
- **Bar Colors**:
- Red bars (128 tokens) appear only for GPT-2 APE and Meta + APE/Meta + RoPE
- Orange bars (256 tokens) appear for all models except GPT-Neo-125M
- Blue bars (512 tokens) appear for all models
### Detailed Analysis
1. **GPT-2 APE**:
- 128 tokens: 20.2%
- 256 tokens: 23.7%
- 512 tokens: 25.0%
- *Trend*: Minimal improvement with longer training.
2. **Meta + APE**:
- 128 tokens: 25.0%
- 256 tokens: 53.6%
- 512 tokens: 80.9%
- *Trend*: Significant accuracy gains with longer training.
3. **Meta + RoPE**:
- 128 tokens: 25.0%
- 256 tokens: 35.7%
- 512 tokens: 95.3%
- *Trend*: Steep improvement, especially at 512 tokens.
4. **GPT-Neo-125M**:
- Only 512 tokens shown: 24.9%
- *Note*: No data for 128/256 tokens in the chart.
### Key Observations
- **Meta + RoPE (512 tokens)** achieves the highest accuracy (95.3%), outperforming all other configurations.
- **GPT-Neo-125M** shows the lowest accuracy (24.9%) but lacks data for shorter training lengths.
- **Meta + APE** demonstrates the largest relative improvement (25.0% → 80.9%) when doubling training length from 128 to 512.
- **GPT-2 APE** shows the least sensitivity to training length changes.
### Interpretation
The data suggests that:
1. **Training Length Matters**: Longer training consistently improves accuracy across models, with Meta + RoPE showing the most dramatic gains.
2. **Architecture Impact**: Meta + RoPE's superior performance at 512 tokens implies architectural advantages over GPT-2 and GPT-Neo-125M.
3. **Data Gaps**: The absence of 128/256 token results for GPT-Neo-125M raises questions about whether:
- The model was not trained on shorter lengths
- It underperforms so severely that results were omitted
4. **Diminishing Returns**: While all models improve with longer training, the rate of improvement varies significantly, with Meta + RoPE showing near-linear scaling.
This analysis highlights the interplay between model architecture and training duration in determining performance on segment counting tasks. The stark contrast between Meta + RoPE and other models at maximum training length suggests that architectural innovations (e.g., RoPE positional encoding) may be critical for high-accuracy performance.