TECHNICAL ASSET FINGERPRINT
f70e7c314a7e7a55fd2f75f8
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
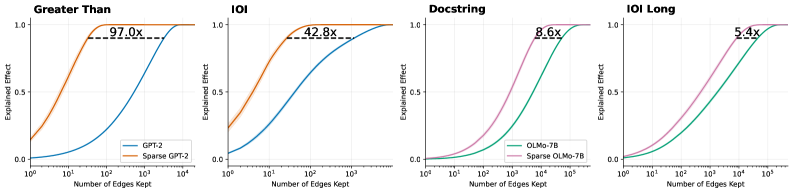
## Chart: Explained Effect vs. Number of Edges Kept for Different Models and Tasks
### Overview
The image presents four line charts comparing the "Explained Effect" as a function of the "Number of Edges Kept" for different models (GPT-2 and OLMo-7B) and tasks ("Greater Than", "IOI", "Docstring", and "IOI Long"). Each chart compares a standard model with its sparse counterpart. The x-axis (Number of Edges Kept) is on a logarithmic scale. The charts show how well the models perform as the number of edges is reduced.
### Components/Axes
* **Titles (Top of each chart):**
* Chart 1: "Greater Than"
* Chart 2: "IOI"
* Chart 3: "Docstring"
* Chart 4: "IOI Long"
* **Y-axis (Shared):**
* Label: "Explained Effect"
* Scale: 0.0 to 1.0, with tick marks at 0.0 and 0.5.
* **X-axis (Shared):**
* Label: "Number of Edges Kept"
* Scale: Logarithmic, ranging from 10^0 to 10^4 (Charts 1 & 2) and 10^0 to 10^5 (Charts 3 & 4).
* **Legends (Bottom-left of each chart):**
* Chart 1 & 2:
* Blue line: "GPT-2"
* Orange line: "Sparse GPT-2"
* Chart 3 & 4:
* Green line: "OLMo-7B"
* Pink line: "Sparse OLMo-7B"
* **Annotations:** Each chart has an annotation indicating the "x" factor, representing the ratio of edges kept between the dense and sparse models at the point where the explained effect plateaus.
### Detailed Analysis
**Chart 1: Greater Than**
* **GPT-2 (Blue):** The explained effect increases slowly from 0 to 1 as the number of edges kept increases from 10^0 to approximately 10^3.
* At 10^0 edges, the explained effect is approximately 0.1.
* At 10^1 edges, the explained effect is approximately 0.2.
* At 10^2 edges, the explained effect is approximately 0.6.
* At 10^3 edges, the explained effect is approximately 0.95.
* At 10^4 edges, the explained effect is approximately 1.0.
* **Sparse GPT-2 (Orange):** The explained effect increases rapidly from approximately 0.2 to 1 as the number of edges kept increases from 10^0 to approximately 10^2.
* At 10^0 edges, the explained effect is approximately 0.2.
* At 10^1 edges, the explained effect is approximately 0.9.
* At 10^2 edges, the explained effect is approximately 1.0.
* **Annotation:** "97.0x" is displayed above a dashed horizontal line at an explained effect of approximately 0.92.
**Chart 2: IOI**
* **GPT-2 (Blue):** The explained effect increases slowly from approximately 0.1 to 1 as the number of edges kept increases from 10^0 to approximately 10^3.
* At 10^0 edges, the explained effect is approximately 0.1.
* At 10^1 edges, the explained effect is approximately 0.3.
* At 10^2 edges, the explained effect is approximately 0.8.
* At 10^3 edges, the explained effect is approximately 0.95.
* At 10^4 edges, the explained effect is approximately 1.0.
* **Sparse GPT-2 (Orange):** The explained effect increases rapidly from approximately 0.3 to 1 as the number of edges kept increases from 10^0 to approximately 10^2.
* At 10^0 edges, the explained effect is approximately 0.3.
* At 10^1 edges, the explained effect is approximately 0.8.
* At 10^2 edges, the explained effect is approximately 1.0.
* **Annotation:** "42.8x" is displayed above a dashed horizontal line at an explained effect of approximately 0.92.
**Chart 3: Docstring**
* **OLMo-7B (Green):** The explained effect increases slowly from approximately 0 to 1 as the number of edges kept increases from 10^0 to approximately 10^5.
* At 10^0 edges, the explained effect is approximately 0.0.
* At 10^1 edges, the explained effect is approximately 0.02.
* At 10^2 edges, the explained effect is approximately 0.05.
* At 10^3 edges, the explained effect is approximately 0.15.
* At 10^4 edges, the explained effect is approximately 0.6.
* At 10^5 edges, the explained effect is approximately 0.95.
* **Sparse OLMo-7B (Pink):** The explained effect increases rapidly from approximately 0 to 1 as the number of edges kept increases from 10^0 to approximately 10^4.
* At 10^0 edges, the explained effect is approximately 0.0.
* At 10^1 edges, the explained effect is approximately 0.05.
* At 10^2 edges, the explained effect is approximately 0.1.
* At 10^3 edges, the explained effect is approximately 0.3.
* At 10^4 edges, the explained effect is approximately 0.9.
* At 10^5 edges, the explained effect is approximately 1.0.
* **Annotation:** "8.6x" is displayed above a dashed horizontal line at an explained effect of approximately 0.92.
**Chart 4: IOI Long**
* **OLMo-7B (Green):** The explained effect increases slowly from approximately 0 to 1 as the number of edges kept increases from 10^0 to approximately 10^5.
* At 10^0 edges, the explained effect is approximately 0.0.
* At 10^1 edges, the explained effect is approximately 0.05.
* At 10^2 edges, the explained effect is approximately 0.1.
* At 10^3 edges, the explained effect is approximately 0.2.
* At 10^4 edges, the explained effect is approximately 0.6.
* At 10^5 edges, the explained effect is approximately 0.95.
* **Sparse OLMo-7B (Pink):** The explained effect increases rapidly from approximately 0 to 1 as the number of edges kept increases from 10^0 to approximately 10^4.
* At 10^0 edges, the explained effect is approximately 0.0.
* At 10^1 edges, the explained effect is approximately 0.1.
* At 10^2 edges, the explained effect is approximately 0.2.
* At 10^3 edges, the explained effect is approximately 0.4.
* At 10^4 edges, the explained effect is approximately 0.8.
* At 10^5 edges, the explained effect is approximately 1.0.
* **Annotation:** "5.4x" is displayed above a dashed horizontal line at an explained effect of approximately 0.92.
### Key Observations
* In all four charts, the sparse models (Sparse GPT-2, Sparse OLMo-7B) achieve a similar "Explained Effect" to their dense counterparts (GPT-2, OLMo-7B) with significantly fewer edges.
* The "x" factor annotations indicate the ratio of edges required by the dense model compared to the sparse model to achieve a similar level of "Explained Effect".
* The "Greater Than" task shows the largest difference between the dense and sparse models (97.0x), while "IOI Long" shows the smallest difference (5.4x).
### Interpretation
The charts demonstrate that sparse models can achieve comparable performance to dense models while using significantly fewer parameters (edges). This suggests that many connections in dense models are redundant and can be pruned without significantly impacting performance. The "x" factor annotations quantify the degree of redundancy for each task. The "Greater Than" task appears to be the most amenable to sparsification, while "IOI Long" is the least. This could be due to the inherent complexity of each task and the specific architecture of the models. The data suggests that sparse models are a promising approach for reducing the computational cost and memory footprint of large language models.
DECODING INTELLIGENCE...
EXPERT: gemini-3.1-pro-preview VERSION 1
RUNTIME: gemini/gemini-3.1-pro-preview
INTEL_VERIFIED
## Line Charts: Explained Effect vs. Number of Edges Kept Across Four Tasks
### Overview
The image consists of a 1x4 grid of line charts comparing the performance of standard language models against their "Sparse" counterparts across four different tasks: "Greater Than", "IOI", "Docstring", and "IOI Long". The charts illustrate how rapidly each model achieves a high "Explained Effect" as the "Number of Edges Kept" increases. In all four panels, the sparse models achieve higher explained effects with significantly fewer edges than the standard models.
### Components/Axes
All four charts share identical axis definitions and scales:
* **Y-Axis:** Labeled "Explained Effect". The scale is linear, with major tick marks and gridlines at **0.0, 0.5, and 1.0**.
* **X-Axis:** Labeled "Number of Edges Kept". The scale is logarithmic (base 10). The range varies slightly depending on the model being evaluated:
* Charts 1 & 2 (GPT-2): Ticks at **$10^0$, $10^1$, $10^2$, $10^3$, $10^4$**.
* Charts 3 & 4 (OLMo-7B): Ticks at **$10^0$, $10^1$, $10^2$, $10^3$, $10^4$, $10^5$**.
* **Legends:**
* Located in the bottom-right corner of the first chart ("Greater Than"):
* **Blue Line:** GPT-2
* **Orange Line:** Sparse GPT-2
* *(Note: This color coding applies to the second chart, "IOI", as well).*
* Located in the bottom-right corner of the third chart ("Docstring"):
* **Green Line:** OLMo-7B
* **Pink/Purple Line:** Sparse OLMo-7B
* *(Note: This color coding applies to the fourth chart, "IOI Long", as well).*
* **Annotations:** Each chart features a horizontal dashed black line connecting the two curves at approximately the y = 0.9 level. Above this dashed line is a text label indicating a multiplier (e.g., "97.0x"), representing the ratio of edges required by the standard model versus the sparse model to achieve that specific Explained Effect.
### Detailed Analysis
#### Panel 1: Greater Than (Far Left)
* **Trend Verification:** The orange line (Sparse GPT-2) rises sharply from the y-intercept, reaching maximum effect quickly. The blue line (GPT-2) remains low initially and requires a much higher number of edges to rise.
* **Data Points (Approximate):**
* **Sparse GPT-2 (Orange):** Starts at y ~ 0.15 (x=$10^0$). Reaches y=0.5 at x ~ $10^1$. Reaches y=0.9 at x ~ 30. Reaches y=1.0 just after x=$10^2$.
* **GPT-2 (Blue):** Starts at y ~ 0.0 (x=$10^0$). Reaches y=0.5 at x ~ $10^3$. Reaches y=0.9 at x ~ 3,000. Reaches y=1.0 near x=$10^4$.
* **Annotation:** A dashed line at y ~ 0.9 connects the curves. The label reads **97.0x**, indicating GPT-2 requires 97 times more edges than Sparse GPT-2 to reach this level of explained effect.
#### Panel 2: IOI (Center Left)
* **Trend Verification:** Similar to Panel 1, the orange line (Sparse GPT-2) ascends much faster than the blue line (GPT-2).
* **Data Points (Approximate):**
* **Sparse GPT-2 (Orange):** Starts at y ~ 0.25 (x=$10^0$). Reaches y=0.5 at x ~ 5. Reaches y=0.9 at x ~ 40. Reaches y=1.0 near x=$10^2$.
* **GPT-2 (Blue):** Starts at y ~ 0.05 (x=$10^0$). Reaches y=0.5 at x ~ $10^2$. Reaches y=0.9 at x ~ 1,700. Reaches y=1.0 near x=$10^4$.
* **Annotation:** A dashed line at y ~ 0.9 connects the curves. The label reads **42.8x**.
#### Panel 3: Docstring (Center Right)
* **Trend Verification:** The pink line (Sparse OLMo-7B) rises steadily, preceding the green line (OLMo-7B), which follows a similar but delayed trajectory along the x-axis.
* **Data Points (Approximate):**
* **Sparse OLMo-7B (Pink):** Starts at y ~ 0.0 (x=$10^0$). Reaches y=0.5 at x ~ $10^3$. Reaches y=0.9 at x ~ 4,000. Reaches y=1.0 near x=$10^4$.
* **OLMo-7B (Green):** Starts at y ~ 0.0 (x=$10^0$). Reaches y=0.5 at x ~ $10^4$. Reaches y=0.9 at x ~ 35,000. Reaches y=1.0 near x=$10^5$.
* **Annotation:** A dashed line at y ~ 0.9 connects the curves. The label reads **8.6x**.
#### Panel 4: IOI Long (Far Right)
* **Trend Verification:** The pink line (Sparse OLMo-7B) rises before the green line (OLMo-7B), though the gap between them appears visually narrower than in the GPT-2 charts.
* **Data Points (Approximate):**
* **Sparse OLMo-7B (Pink):** Starts at y ~ 0.0 (x=$10^0$). Reaches y=0.5 at x ~ 500. Reaches y=0.9 at x ~ 10,000. Reaches y=1.0 near x=$10^5$.
* **OLMo-7B (Green):** Starts at y ~ 0.0 (x=$10^0$). Reaches y=0.5 at x ~ 3,000. Reaches y=0.9 at x ~ 54,000. Reaches y=1.0 slightly after the pink line.
* **Annotation:** A dashed line at y ~ 0.9 connects the curves. The label reads **5.4x**.
### Key Observations
1. **Consistent Superiority of Sparse Models:** In every task evaluated, the "Sparse" version of the model (Sparse GPT-2, Sparse OLMo-7B) achieves a high "Explained Effect" using orders of magnitude fewer "Edges" than the baseline models.
2. **Varying Efficiency Gains:** The efficiency multiplier (annotated at the ~0.9 Explained Effect mark) varies drastically depending on the model and task. The gain is massive for GPT-2 on the "Greater Than" task (97.0x) but much more modest for OLMo-7B on the "IOI Long" task (5.4x).
3. **Model Scale Differences:** The x-axis reveals that the OLMo-7B models generally require more edges overall (up to $10^5$) to reach a 1.0 explained effect compared to the GPT-2 models (which max out around $10^4$), reflecting the likely difference in the total size and complexity of the underlying models.
### Interpretation
These charts are highly indicative of research in **mechanistic interpretability** or **network pruning** within Large Language Models (LLMs).
* **"Edges Kept"** likely refers to the connections between nodes, attention heads, or MLP layers within the neural network's computational graph (often referred to as a "circuit").
* **"Explained Effect"** represents how well a sub-network (the kept edges) can replicate the performance or specific behavior of the full, unpruned model on a specific task (like "Greater Than" or "Indirect Object Identification - IOI").
**The core finding demonstrated by this data is that "Sparse" models are vastly more efficient for circuit discovery.** The data proves that by using a sparse variant of a model, researchers can isolate the specific pathways (edges) responsible for a task while throwing away the vast majority of the network. For example, in the "Greater Than" task, the sparse GPT-2 model can explain ~90% of the model's behavior using nearly 100 times fewer connections than standard GPT-2. This suggests that the sparse models have highly localized, disentangled representations for these tasks, making them significantly easier to interpret and analyze than their dense counterparts.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
## Line Graphs: Explained Effect vs. Number of Edges Kept
### Overview
The image contains four line graphs arranged in a 2x2 grid, comparing the performance of sparse vs. non-sparse models across different tasks. Each graph plots "Explained Effect" (y-axis, 0.0–1.0) against "Number of Edges Kept" (x-axis, logarithmic scale: 10⁰ to 10⁵). The graphs are labeled "Greater Than," "IOI," "Docstring," and "IOI Long," with distinct color-coded lines for each model variant.
### Components/Axes
- **X-axis**: "Number of Edges Kept" (logarithmic scale: 10⁰, 10¹, 10², 10³, 10⁴, 10⁵).
- **Y-axis**: "Explained Effect" (linear scale: 0.0 to 1.0).
- **Legends**:
- **Top-left graphs ("Greater Than," "IOI")**:
- Blue line: "GPT-2" (non-sparse).
- Orange line: "Sparse GPT-2" (sparse).
- **Bottom-right graphs ("Docstring," "IOI Long")**:
- Teal line: "OLMo-7B" (non-sparse).
- Pink line: "Sparse OLMo-7B" (sparse).
- **Annotations**: Multipliers (e.g., "97.0x," "42.8x") indicate efficiency gains of sparse models over non-sparse baselines.
### Detailed Analysis
1. **Greater Than**
- **Sparse GPT-2 (orange)**: Rapidly plateaus near 1.0 at ~10² edges, annotated with "97.0x" efficiency gain.
- **GPT-2 (blue)**: Gradually approaches 1.0, requiring ~10³ edges.
2. **IOI**
- **Sparse GPT-2 (orange)**: Plateaus near 1.0 at ~10² edges, annotated with "42.8x" efficiency gain.
- **GPT-2 (blue)**: Reaches 1.0 at ~10³ edges.
3. **Docstring**
- **Sparse OLMo-7B (pink)**: Plateaus near 1.0 at ~10³ edges, annotated with "8.6x" efficiency gain.
- **OLMo-7B (teal)**: Reaches 1.0 at ~10⁴ edges.
4. **IOI Long**
- **Sparse OLMo-7B (pink)**: Plateaus near 1.0 at ~10⁴ edges, annotated with "5.4x" efficiency gain.
- **OLMo-7B (teal)**: Reaches 1.0 at ~10⁵ edges.
### Key Observations
- **Efficiency Gains**: Sparse models achieve near-maximum explained effect with significantly fewer edges than non-sparse models (e.g., 97.0x faster in "Greater Than").
- **Diminishing Returns**: Non-sparse models show gradual improvement, while sparse models plateau early, suggesting limited benefit from additional edges.
- **Task-Specific Performance**: Efficiency gains vary by task (e.g., "Greater Than" has the highest multiplier at 97.0x).
### Interpretation
The data demonstrates that sparse models (e.g., Sparse GPT-2, Sparse OLMo-7B) drastically reduce computational requirements while maintaining high performance, as evidenced by their early plateaus and high efficiency multipliers. This suggests sparse architectures are optimal for resource-constrained environments. The diminishing returns for non-sparse models highlight the importance of edge selection in model efficiency. The task-specific multipliers indicate that sparsity benefits vary depending on the problem domain.
DECODING INTELLIGENCE...